Check out the latest javascript, tech and web development links from the daily linkblog.
-
The blog has moved
blogging writing
I have had to migrate my main homepage and as part of the move I decided to consolidate the blog, linkblog and podcast sites into the new website.
There is also a latest page where you can see the newest content from all 3.
-
Alternative Nations
blogging writing
I got inspired while listening to this excellent mix - Maybe you can guess where exactly, listen as you read
Where do you come from?
Hmmm, well I come from maaaany places…
I come from jazz
I come from rock
I come from folk
I come from pop
I come from heavy metal
I come from grunge
I come from punk rock
I come from ska
I come from britpop
I come from hip hop
I come from gangsta rap
I come from breakbeat
I come from drum and base
I come from house
I come from ambient
I come from disco
I come rave
I come from acid
I come from reggae
I come from dub
I come from dancehall
I come from bangra
I come from live music
I come from radio
I come from music festivals
I come from carnivals
I come from parties
I come from after parties
I come from after after after parties
I come from Ibiza
I come from noise
I come from experimental
I come from podcasting
I come from pubs
I come from riverboats
I come from front of house
I come from kitchens
I come from chefs
I come from chalkboards
I come from daily menus
I come from split shifts
I come from sledging
I come from skiing
I come from snowboarding
I come from tennis
I come from camping
I come from basketball
I come from baseball
I come from javascript
I come from css
I come from html
I come from sql
I come from bash
I come from perl
I come from python
I come from java
I come from c++
I come from linux
I come from unix
I come from irix
I come from windows
I come from engineering
I come from science
I come from feature film visual effects
I come from software startups
I come from software development
I come from web2.0
I come from APIs
I come from user generated content
I come from bit torrent
I come from copy left licensing
I come from gnu
I come from free software
I come from open source
I come from blogging
I come from photo journaling
I come from videoblogging
I come from hacking
I come from making
I come traveling
I come from road trips
I come from digital nomadism
I come from Europe
I come from the Middle East
I come from the USA
I come from Canada
I come from South East Asia
I come from bad relationships
I come from sobriety
I come from COVID
I come from loving life
I come from racism
I come from abuse
I come from exclusion
I come from blocking
I come from surveillance
I come from police (fake?) brutality
I come from security guard / tuk tuk / taxi / delivery bike mafia intimidation
I come from stalkers
I come from capture gangs
I come from exploitation
I come from conspiracies of silence
I come from an infinite list of contradictions
I come from years of continuous and co-ordinated daily harassment
I come from starvation
I come from thirst
I come from torture
I come from crucifixion
I come from homelessness
-
The occasional listening issues of my head
blogging writing
I previously wrote about reading and memory issues I some times have. Around about the same time I wrote that, I also wrote another piece about audio listening issues. I never published it though. This week I’m looking for blogging topics, and maybe it helps someone out there, so here it is.
Similar to my occasional reading issues, I’ve noticed that I also at times have issues listening to audio. It takes a very similar shape to the reading issues, in that it feels like some sort of buffering is happening.
I can hear all the words and I’ll be listening attentively. Then I notice that I’ve sort of blanked out for some amount of time, and I can’t remember what I’ve just been listening to. I then have to rewind to a place I recognise, sometimes it’s quite a long ways back, occasionally a minute or two, but usually several seconds.
It also happens when my mind is being triggered by the audio I’m listening to. I will start to formulate lots and lots of questions about what I’m listening to, and in doing so I loose my place in the ongoing audio. Mood also has an affect.
At times it’s annoyingly small side thoughts that totally derail my listening, I’m left trying to remember what I was listening to, and I simply can’t remember, conscious that the not remembering is causing me to miss yet more stuff because the audio I can hear is basically going straight to the void. And so it gets even worse.
At times it gets so bad that the only way I can absorb anything at all is to write copious amounts of notes. I have to pause and rewind, continuously and write notes, so I understand what’s going on, but I loose the flow of the overall audio, and I suspect that it sort of spoils my long term memory of the piece, because a lot of the subtleties and nuance get clobbered.
Taking a break helps a bit, and having food + something to drink. In case it wasn’t already abundantly obvious starvation and thirst does not help one bit, something which I have been unfortunate enough to verify.
-
The HTML5 Phone
blogging writing
I’ve been having this re-occurring thought. I don’t know how feasible it is, but I wanted to write about it just in case. Wouldn’t it be awesome if there was an HTML5 phone?
The HTML5 phone would have all it’s UI built from HTML, CSS & Javascript, would likely run on a minimal Linux distro. Native apps would run in a custom NodeJS runtime, perhaps using something like Electron. It would be great for web developers, with the possibility to develop for the phone, on the phone. It could also leverage the web platform via PWAs. There’s a lot of variation possible, but the focus would be on HTML5 everywhere.
I think there are a lot of current trends that could make this crazy pipe-dream a reality that could gain traction:
- Recent big push towards open web standards
- Move to privacy, phone OSs like Purism, the e/OS phone
- More alternative custom javascript runtimes
- Phone hardware is fast
- There are a lot of web developers out in the world at this stage
Wouldn’t a progressively enhanced OS be cool? Always know, that the basic apps you need will always work, no matter what phone you have.
It might not even be that difficult to start. Initially just create a bare minimum suite of apps, progressive enhancement style, that just do the very basics of the following apps:
- Browser
- Camera
- Music
- Video
- Notes
- File Explorer
- Contacts
- Messaging
- Calling
Build them as super simple web apps first. Once there’s something functional, enhance as needed, port to native apps etc.
The most difficult app is probably the web browser. I had initially thought that you could just have a browser and do everything with PWAs, but I think it’s sensible to have native apps to make sure you’re not forced to wait for web platform features.
Anyhow some interesting posts about creating browsers that I found, just to get a sense of what’s involved:
- How to get started building a web browser?
- How to build a web browser – Part 1: Specifications
- Building a Web Browser Using Electron
Yeah I know it’s a sort of crazy half baked idea, but I just keep thinking how awesome it would be, even if it was quite rough around the edges initially.
As a web developer, I’d like to have more control around my phone / mobile / tablet experience, so why not just do it all in HTML5?
-
OS Progressive Enhancement
blogging writing
I’m trying to get back into the blogging flow after a period of not writing much, so the next few posts are likely going to be a bit light on well-thought-outness, which isn’t even a word, but whatever. The enemy for me right now is getting bogged down, just trying to keep moving…
I really like the practice in web development to create websites using progressive enhancement. Essentially you first create a bare minimum app using mostly HTML, and platform features, make sure that works, even if it looks a bit weird. The key thing is that functionality-wise it’s operational.
Then you enhance that with styling using CSS, and improve the functionality using javascript. This ensures that in pretty much any situation, even if for some reason the CSS and Javascript fail to load or get blocked, you still have an operational website.
I’d like to have something similar with Operating Systems. I’d like to know that no matter which OS I have to use, be it Desktop, Laptop or Mobile, that the default apps provide a minimum of functionality so I can at least do basic things.
Major apps like contacts, notes, browser etc could have minimum functionality specs, so you could quickly see where you could move to and still be functional.
Slightly scattered thoughts, but the gist of it is progressive enhancement for operating systems.
-
The Big Tech Sandwich
blogging writing
Sandwich
- Tech
- Culture
- Religion & history
Background
I recently wrote a series of newsletters where I explored the idea of a Big Tech Sandwich. A mental model for how to think about tech in the most broad context, how to handle the mess that is society. Hopefully it’s helpful in moving things forward so that we can make the world a slightly better place for the next generation. I personally have found it useful.
This blog post is a sort of summary, to have something I can point to in the future. I’m going through a moderately severe case of writers block the past few weeks, combined with very patchy internet access, which isn’t a great combination. Consequently this post is unlikely going to be a super smooth read, but I think the ideas are interesting. Consider this a v1, I’ll update later, better to have something published than nothing at all.
These were the newsletters:
- Mid-week special: Navigating the big tech mess (Wednesday 27th April, 2022)
- The full full stack, and the weight of history (Saturday 30th April, 2022)
- The Big Sandwich (Saturday 7th May, 2022)
- Culture Smash (Saturday 14th May, 2022)
- Demons be gone (Saturday 21st May, 2022)
- Mid-week Special: Dilemma Addendum (Tuesday 24th May, 2022)
A quick note about culture because it means different things to different people. When I’m speaking about culture here I’m mostly thinking about culture of society rather than something like company culture. They are similar and related, but I’m thinking more about music, art, movies, books in general, with large movements that develop mostly organically.
Scale
Where is tech in the bigger picture? We that spend most of our time in the tech industry have a tendency to over play how important we think tech is in society. My observation is that, yes things are complicated, and yes we’ve made a lot of progress, but things are a mess, much messier than is immediately obvious. When you start looking around it’s a bit unnerving to realise. Things are a mess.
But wait, it gets worse, technology is really just a small part of our overall culture. We have some effect on it, but culture is huge, and guess what? It’s also a mess, a really big mess actually.
As you zoom out some more, the timescales increase dramatically. You soon get to the scale of history and religion. You realise how small tech is in the overall picture. Oh yeah and by the way, you thought tech and culture were a mess, well let me tell you, things get mind bogglingly messy at this level. It’s literally unbelievable that we are all living side by side in this small rock we call Earth.
Society, culture, history and even religion play a much much bigger role than we like to admit to ourselves. This sort of stuff is absorbed automatically as we grow up, we don’t even notice a lot of it.
Culture is important, but very difficult to get right. It can help us build temporary scaffolding around difficult areas of our shared history. It gives us the ability to move forward in the present while being informed by the past, but without getting too bogged down. It’s by no means perfect, there are a lot of bumps in the road in some places.
I wrote quite a bit about the example of how popular culture helped to integrate very different parts of UK society. That issue:
- Culture Smash (Saturday 14th May, 2022)
I also wrote a related but different piece a bit earlier which is relevant:
- Punk Rock Internet (Saturday 19th March, 2022)
The future
Things are actually getting better. When you stand back and see the bigger picture over thousands of years, it’s apparent that things are getting better. The large empires of the past that ruled in very violent ways are becoming much more modern, slavery has been abolished, we collaborate across borders, in different languages, build things together, and we do it using tech.
It’s difficult though because we have all these tough histories that we’ve all been through. There are some very scary things that happened, and for many it’s still horrendous. Some people have a lot, others don’t have much.
So that’s my first attempt at a summary, it glosses over a lot. To get a better sense you really need to read some of the newsletters, and listen to some the podcasts linked in those issues. I encourage you to do that, it’s fascinating stuff. We can get culture moving and popping again, and in even more diverse ways. It might even be fun.
It’s a mess, but slowly, one step at a time, we can together make it better for the next generation and ourselves.
-
Budism vs Christianity - WTF World?
blogging writing
Fat Budha: Abundance!
Jesus nailed to cross: Everything is my fault!
WTF world? Seriously.
-
The good homeless person’s (and society’s) dilemma - Addendum
blogging writing
An additional thought to the post from a few days ago.
The non-homeless man is possibly part of a Capture Gang - See section about audience capture for details.
-
The good homeless person’s (and society’s) dilemma
blogging writing
A homeless person has a series of daily run-ins with a non-homeless person, where the non-homeless person is unknowingly doing something that puts the homeless person in some sort of danger. The danger could lead to a bad thing happening that has the potential to eventually cause the homeless person’s death.
The homeless person tries each day to tell the non-homeless person that he’s being dangerous but the non-homeless person simply does not see the danger.
After a few days the non-homeless person realises what it was that he was doing that was dangerous and stops doing the dangerous thing.
Meanwhile everybody else has stopped giving the ‘crazy’ homeless person money, because they don’t want to incentivise his ‘crazy’ behaviour, so he’s been starving and thirsty for several days.
The homeless person essentially had to pay in advance to fix somebody else’s problem.
Eventually, if this sort of thing keeps happening, the homeless person doesn’t have enough flesh on his body and so he dies.
Also, the non-homeless person might be lying.
-
Npm installing multiple private Github repos using ssh aliases
blogging programming
When you are developing in NodeJS it’s often useful to be able to install private modules.
The main ways to do that are:
- Github Packages using Personal Access Token (PAT)
- Private Github repo using Personal Access Token (PAT)
- Private Github repo using Deploy Keys
Apparently (1) is the most popular among developers, however it requires setup and management of additional workflows to create the Github Package.
(2) Only works for a maximum of 1 private repo.
(3) Works for 1 private repo, and can be extended using ssh aliases to work with multiple private repos.
Deploy keys are also more granular in terms of security than PAT.
This article focuses on method (3).
Github has an example repo that demonstrates how to install a private repo using deploy keys. It’s worth testing that out.
If you try the same methodology for installing more than 1 private repo in the same workflow, you’ll run into an issue. The reason being that Github doesn’t allow you to re-use the same deploy key across repos, and by default npm will use the default ssh private key (~/.ssh/id_rsa), of which there is only one.
However if you configure ssh to use aliases, you can specify a different private key for each alias, and then use those aliases in your package.json to specify the private module dependency.
Read more details about how to do that in the Github docs.
For example if you had 3 private repos:
- username/repo1
- username/repo2
- username/repo3
Where repo1 installs both repo2 and repo3, then add an ssh config ($HOME/.ssh/config) as follows:
Host github.com-repo2 Hostname github.com IdentityFile=/home/user/.ssh/private_key_repo2 Host github.com-repo3 Hostname github.com IdentityFile=/home/user/.ssh/private_key_repo3Then specify the modules like so in repo1’s package.json:
"dependencies": { … "repo2": "git+ssh://[email protected]:username/repo2", "repo3": "git+ssh://[email protected]:username/repo3", … }It’s important to specify the protocol correctly. Without ‘git+ssh://‘ the install completes but none of the files actually get installed. Instead some type of symlink gets created. At least that’s what happened in my tests.
Store your private keys in Github secrets, and before your install step, create the private keys on the filesystem from those secrets:
/home/user/.ssh/private_key_repo2and
/home/user/.ssh/private_key_repo3Now in your repo1 workflow you should be able to install all repo1 dependencies using:
npm installIt’s worth having a verify step after install that lists the installed files using ls -l and/or tree.
-
Infected leg wounds
blogging health
I’m still battling with infected leg wounds, but things are a bit better than earlier in the week. I can at least sort of walk now.
What happened? I don’t fully know.
A month ago, a stranger nonchalantly walked up to me in a park, touched my right knee, smiled and walked off. Very weird.
A couple of days later that exact spot started feeling sore. I didn’t think much of it, but I ran out of disinfectant, and it rapidly turned into an abscess.
I got bandages and disinfectant, but then ran out again. I had to use moving tape to secure my last 2 bandages. I was able to get to a pharmacy but the moving tape created more sores, and those turned into more abscesses.
Somehow the abscesses jumped across to my other knee. The whole knee ballooned with one absolutely giant abscess. Over the past few days that has turned into a strip of abscesses that looks oddly like an upside down exclamation point. What are the chances?
Earlier in the week I was worried it might permanently affect my mobility, I could barely walk. I’m now worried about scaring. An improvement but not much better.
Dressing and cleaning these sores has been close to some of the most intense pain I’ve ever experienced. Having to spend literally hours at a time squeezing out puss, with the same intensity and force as an arm wrestle.
Something similar happened to me in India a few years ago, I’ve got a small scar from that experience. Looks like I’ll have a bigger scar this time.
There’s been a lot of unpleasant reactions from people, from mild racism to people finding it hilarious seeing a foreigner in pain.
I know these are a small group overall, but as with trolls in online comments, they can make it seem like the whole world is against you. I’m both mentally and physically bruised at the minute.
You might be wondering: Are you ok?
My response: No not really.
-
My brain's favorite passtime
blogging health
My brain: Do this now or I will delete this…
Me: Yes that does sound interesting, I’ll just finish what I was doing first, it will only take a few seconds
My brain: Too late! this has been deleted, haha, that’ll learn you
Me: Shit, what was I doing again? :(
I think perhaps it happens more often when “the external world” is constantly butting in trying to prompt me todo things that I am already about to do. Eventually it devolves into some sort of race condition, and the only thing you can do is walk and move really really slowly like you are a grandad.
Makes you wonder about alternative scenarios for where grandad’s actually come from, which doesn’t help the situation much either.
-
What I love about loud guitars
blogging music philosophy health
I’ve been listening to loud guitars for about 40 years. That’s quite a long time.
I took a bit of a break from listening to music recently. It was for about two years. It wasn’t something that was planned, life circumstances arranged themselves in such a way that listening was more difficult than it had been previously, I was very busy with other things, and I just sort of stopped.
I was still listening to podcasts, but not music. At some point I listened to a podcast that reminded me about my love for music. It was a strange feeling, like oh-yeah-I-used-to-really-love-music, in that moment I realised that I had basically forgotten. It was the strangest thing, similar to remembering a dream.
I’ve since started listening to all sorts of music again, electronic and band / guitar based. Not loads, but some. I’m so glad that I remembered.
I was listening to some great punk/hardcore/indie/metal recently and was moved to try to put into words the way it makes me feel. The following are extracts of what I wrote.
That thing where you feel like you’ve just been plugged into the mains, and all you want to do is shout YES over and over and over again, really fucking loudly.
It’s like you’ve just been injected with the adrenaline of 1000 horses.
And then the bit finishes and you’re like…”God damn”.
It’s odd because the feeling doesn’t happen in your physical body, you can listen to a whole song and not have any physical change, but the feeling is like it’s in some sort of virtual body, that’s somewhere there in the background, that’s momentarily become very very alive.
It also feels like you are inside the sound, which is odd because it’s the sound that’s inside you, but when you hear that guitar none of that matters anymore, whether it’s you or the sound or whatever, because you’ve just been plugged in, that part of you is alive again.
It’s all the music you’ve ever listened to, all the music videos you’ve ever watched, all the live shows you’ve been to, all the late nights, and all the people you’ve shared those experiences with, in that moment of guitar electricity, they are all there alive again.
It’s such a strong feeling that it’s really bizarre to me that some people can listen to the very same sounds and feel nothing. It just sounds like noise or something.
Those were the bits I wrote. I also love listening to quiter music too, but in that moment, it was all about the loud guitars.
I don’t drink alcohol anymore, it’s been about 3 or 4 years now. I’ve noticed that the music is even better, the drum sounds are crisper, the guitars are more alive, for electronic music, everything is much more hightenned. I notice so much more, it’s like the sound is now in HD when before it was SD. I didn’t expect that at all. It’s awesome.
-
What can web developers learn from the industrialisation of farming?
blogging economics programming
Stuff You Should Know published an interesting episode all about the chicken farming industry. It’s a really great piece, I encourage you to go and listen to it.
The truth between Cage-free and Free-range (Stuff You Should Know Podcast)
I was appalled to learn about how horrendous the conditions are for those animals. It’s shocking to learn about some of the practices that we have developed while industrialising farming, that are normal in our societies. It’s good that people are reconsidering some of these norms.
It also got me thinking about our future with the forward march of technological innovation. We are building ever more complex technologies. Here’s the thought process I can’t seem to shake:
-
Anyone can write software
-
We can build virtual environments
-
There exist people that have industrialised extremely cruel animal farming
-
Those people will use similar techniques on other people, it’s going to happen, it’s just a matter of time
It might not be as visually obvious as chicken cages, in fact it’s likely that it would be designed to fit in our societies and appear normal.
How would we detect instances of people being raised using battery farming techniques?
How would we get out of such a situation if we were already in such a situation?
What about related concepts like bullying? How will that be in the future?
Very relevant and really worth listening to, especially if you are into psychology:
The Dangers of Concept Creep (The Art of Manliness Podcast)
I think it’s worth trying to imagine this sort of thing because ultimately the thing we are farming with the world wide web and the metaverse is ourselves.
Let’s imagine a better future for everyone.
-
-
Reading and memory issues I sometimes have
blogging
Difficult to talk/write about this.
Firstly because it’s not something I’m particularly happy to admit, but also because I’ve only recently become aware of it, or at least aware enough to be able to describe it. It’s something I’ve been in some way aware for years, and it might be getting worse, I can’t tell. So what is it?
Sometimes when I read, I lose the ability to read consistently and with ease. It doesn’t always happen. It seems to happen more when I’ve had a turbulent day, something that’s been happening a lot lately. I get into a state where instead of words coming off the page, so to speak, going through my eyes and being perceived by my brain, in a mostly consistent flow, it feels like there is some sort of buffering going on.
Instead of the words just streaming into my thoughts and brain, my brain seems to change into a mode that operates a bit like that quiz show where the contestants answer questions and have to bank the money at the right time or they loose it. I forget the name of that show, it’s with that dreadfully scary red head woman.
Anyway what happens is this. I read several parts of the sentence and at some point a hole chunk makes it through to my consciousness, all in one go, and on to the next bit that gets slurped in the same way. I have to speed up and slow down in just the right way, or bits start to get missed.
I become aware that it’s happening and I kind of feel when the next chunk is going to be ‘let in’, and that screws up the rythm, and so some chunks get skipped or only partially comprehended, and I find that I have to constantly go back and re-read passages to fill in the gaps.
Perhaps it’s got something to do with being tired. But I’m thinking it might be something else. When it’s not happening, when I’m feeling uncluttered and fresh, the buffering thing doesn’t appear to happen, reading is as smooth as ridding a hover board. When it’s happening it feels like someone is turning a tap on and off.
Something that I’ve noticed that is very different the past several months is that I see a lot of people swinging their arms. This sounds really weird, but at some stage a few months ago basically everyone everywhere started a new exercise routine, where they swing their arms backwards and forwards. Some people do it standing still, others do it while they walk. Sometimes they are doing it while walking backwards.
It’s the new trend where I am. I see literally hundreds of people doing this every single day. That wasn’t always the case. I’m not sure exactly when it started happening. Anyway it’s something that people do, a lot, fair enough, but I wonder if it’s affecting my ability to read smoothly because I’m visually seeing this repetitive up down motion over and over again. It might be completely unrelated, but I think it’s worth mentioning.
I wonder if it’s happening to others without them realising. It’s quite subtle, easy to brush off, especially if you operate day to day with things like caffeine and alcohol. I don’t consume alcohol (it’s been 3-4 years now), and caffeine relatively rarely.
I’ve also noticed my memory at certain times isn’t as good as I expect. I’m trying to remember something, I almost remember it, I can just about feel the thought poping into my head, and then it’s gone, sometimes this happens several times before the memory finally makes it’s way through to my conscious mind.
Occasionally I have to get on with something else, to distract myself from myself, and the memory comes back randomly like a callback function that just got delayed by a very slow internet connection, and a temperamental firewall.
Depending on where you are, you might find people around you that know about this will try to ‘hack’ you. That’s something that definitely happens. It’s a good opportunity to practice keeping calm under pressure, or just to surrender and move on to another place.
That’s my best description of the reading and memory issues I sometimes have. Just putting it out there in case it helps someone else that might be having similar problems.
I haven’t found many ways to improve it apart from just not doing anything for a few hours. I guess meditation can be good too. I do that occasionally. These are not always possible options, sometimes you just have to soldier through to get what you are doing done.
-
Typescript makes function declarations difficult to read
programming javascript
I’m not a massive user of Typescript, though I see it could be very useful in some situations.
The main issue is that I think the additional cognitive load isn’t trivial, and so code that you could easily skim through to get a good idea of what’s going on becomes full of little hurdles. Perhaps it’s something you get used to, but I fear it would seriously impact my ability to read and understand code. It decreases visibility.
Having said that, I really like that you can specify the definitions in JSDoc. That’s cool because the code remains regular, fast to read javascript code. If you are wondering about types, just look at the JSDoc, which is always right next to the function declarations anyway.
Though you don’t get the full power of Typescript using it that way, only the type checking. I’d also like to be able to use interfaces and other object oriented features that come with Typescript.
Which brings me to the point of this post. If you are using full fat Typescript, IMO the way to define the types in the function arguments sucks. Reason being that it uses the colon (:) character.
function equals(x: number, y: number): boolean { return x === y; }I don’t like that because the colon character is for objects declarations. Following years of writing javascript objects, my brain’s muscle memory visually associates that character with objects, so when I’m scanning a page I can easily jump to places on the page without having to fully read the code. Using : in function arg type definitions breaks that for me. I find it’s much more difficult to quickly get my bearings in Typescript code.
I’m also not a fan of long function argument lists and Typescript doubles or triples the length of function argument lists. I feel that function declarations need to be short and to the point. It makes reading code much easier. I don’t find that having the return type is very useful in the function definition. It just feels like clutter to me.
Some people say they like to know the types before they get into the function. Personally I find that once you start reading the code inside a function, it’s usually very obvious to differentiate between objects, arrays, strings, numbers etc. If I want to know the type, it’s preferable to glance at the JSDoc for the function.
There’s a proposal to bring some Typescript syntax to javascript. Personally I’d like it if the type definitions were kept separate, keep function declarations readable! But I would like javascript to have interfaces and additional OO features.
-
Creative Economy vs the Cruelty Economy
philosophy blogging economics
Some thoughts on these two concepts, don’t take these as fact, just some observations, might lead to something interesting, or maybe not.
In the cruelty economy you are rewarded for receiving and disposing of cruelty. People optimise for not being hurt, not getting angry, for catching the purpotraiters of cruelty. Things tend towards a imprisonment.
In the creator economy you are rewarded for receiving creativity and releasing it. People optimise for maximising the creativity, even bad stuff can be good. Things tend towards anarchy.
Things go bad when your capacity to process is exceeded. Creativity turns to cruelty, but perhaps also cruelty turns to creativity.
Real true anger is a capacity problem, it’s the group mis-managing capacity.
It’s a sort of symbiosis, perhaps similar in concept and behaviour to other natural phenomena like the El niño - La niña weather system. In the case of the creator-cruelty economy, ultimately it’s all based on chemical fluctuations in our brains.
It’s a really tough problem to think about, because we are all in the map so to speak, whatever actions we take, including thinking about the dynamic, affects the dynamic, and the balance.
A potential danger is that you get caught in one extreme or the other, without enough capacity to switch. And then you are probably in for a bad time. Smashed against the rocks, over and over again, in plain site.
-
The cruelty economy
web development programming
The Creator Economy has been pretty great.
So many things to watch and listen to. But that’s nothing compared to what’s coming down the pipe: The Cruelty Economy!
Creative Economy + Web3
Crypto, blockchains, memecoins, DAOs, cosplay, algorithms, Anon, AI, brain-computer-interfaces, WOW.
War and peace…AT THE SAME TIME!
Some of you are gonna love it! At least some of the time.
What could possibly go wrong?
With our patented starvation&thirst algorithm, nothing!
-
Cool things that were in web2.0
web development programming social media
Last week I listened to a John Gruber interview with Tom Watson and Daniel Agee, the founders of the photo sharing app Glass. They talked a lot about what it was like during web2.0, including some of the cool things that got developed in that period.
I enjoyed the brief trip down memory lane, an oasis of calm amongst the current madness all around. I spent a few minutes making a list of some of the things I remember, and enjoyed wondering how some of these types of technologies and trends could blend with things in web3.0.
Here’s that list:
- Rocketboom, Ze Frank, and videoblogging
- Citizen journalism
- Creative Commons licensing
- Crowd funding
- Community events and meet-ups
- The Maker movement
- 3D printing
- Photo sharing
- Video streaming
- Online maps and navigation
- Blogging and RSS
- Live photo feeds from events with photos displaying on your desktop as they are taken
- Journalism integrated with data analysis tools
- Social media
- Newsrooms integrating social media into their broadcasts
- Wikipedia
- APIs everywhere
- Web services - AWS, Azure etc
- Podcasting and podcast tools
- Open source hardware
- Open source software
- Github repos and actions
- Bit torrent for sharing assets with listeners to collaborate on
- User Generated Content
- Live video streaming mixed with forum/chat rooms with bots that trigger video and audio overlays when events like tipping occurs
- Gifs
- Memes
- Newsletters
- Weird one offs that never took off like Chat Roulette
Some of these were around before web2.0, but got very popular during web2.0 and arguably some were developed more recently but IMO feel very web2ish. Nonetheless when I think about web2.0, these are some of the things that come to mind.
-
My unsophisticated view on whether we have free will
philosophy blogging
People are always talking about this in podcasts and around the internet, and I suppose it’s all quite interesting, but I just wanted to have some clear thoughts about it myself. So I spent a few minutes thinking about it and this is what I came up with.
It’s probably completely wrong. I wouldn’t take this as life advice.
Do we have free will?
Yes. Because…
-
You have a sort of biological choice algorithm in your head, implemented from neurons organised in neural networks, and it develops in your brain over time, and at any one time that choice algorithm is used to make choices that act on the inputs your brain is receiving. The choice is independent from the inputs, rather than being somehow packaged up and smuggled into your brain along with the inputs
-
We have the ability to introspect, so in principle we have the ability to observe and see instances of unfree coercion, and change our thought processes accordingly - YMMV, every person’s situation is very different, some have a lot more external pressures than others, which isn’t always bad, but it definitely can be
-
If you remove everything, so you are an astronaut floating in the emptiness of space, you can still make choices
Therefore humans have free will. In this view, free will is very similar to independence of thought.
Feels kind of good to have that written down, at least I’ve got something I can point to now.
-
-
Offline
web development offline
Yesterday I wrote about the idea of offline pull requests. It wasn’t a fully formed idea, more of an observation that the current git tooling could improve the offline experience. In the modern, always on, always connected world, the idea of offline might sound a bit strange or out-dated. It might also seem a bit weird for a web developer to be interested in offline because developing for the web is all about being connected.
I like the idea of being able to move relatively seamlessly between online and offline. I’ve found though, that the offline experience is often lacking.
For example, Safari has a feature called Reading Lists. It’s cool and I’ve been using is a lot recently. With a couple of clicks you can add a page to your reading list. It’s s bit like a bookmark, but in addition to saving the url, it has the ability to save the entire page, so you can read it later offline. When it works, it’s amazing.
I’ve found that my workflow has changed significantly. Instead of endlessly infiniti scrolling, I can spend 10-15 minutes in the morning, skimming through stuff in my feeds, adding what looks interesting to the reading list, then disconnecting. At a later point in the day, or maybe the next day, when I have some time, I can read through the articles, make notes, have ideas, write blog posts etc. Awesome right, so what’s the problem?
There are a few. First and foremost it doesn’t work on all websites. I have no idea why that is, I guess websites have to be written in a special way for it to work. I haven’t had time to research this yet, I’d like to know why it only works for some websites. Another issue is that there is no indication that the site isn’t “offlineable”. You click “Save Offline” and it looks like it saved. Later you try to open the site while offline and you just get an error message, I forget the actual wording, but it feels a lot like “You can’t read that because you are offline, idiot”. You used the feature as advertised, and you still got a slap in the face. You keep calm, and carry on with your life. It happens a lot.
I found an option, buried deep in the app settings, that automatically saves each item you add for offline reading. Nice feature, definitely makes things better, but you still get slapped in the face witch the error messages a lot, because loads of sites just aren’t “offlinable”.
I wonder if website owners just don’t like offline because it blocks the click info they get when you are online, maybe it somehow affects their add revenue. With better tooling that’s an issue that could be solved.
It would be great if in addition to the saved page, each linked item in the saved page was also saved for offline reading. And wouldn’t it be cool if there was a way to click a button to get the current page, as well as a selection of other popular articles on that site.
Matt Mulenweg when in Antarctica, prepares for his trip by downloading portions of Wikipedia. Cool idea. I wonder how he does that, I guess he’s got a special Wikipedia reader tool. I’d like to be able to do that sort of thing in more places. Like when browsing a Github repo, save the site, but also save the associated documentation site. I wonder if Progressive Web Apps (PWAs) might be in some way a solution here.
Reading Lists are useful but they don’t work with video. I miss watching Youtube videos. With an offline workflow, there’s no way at the minute to watch video. In the early days of podcasting, people often put videos in their feeds, that was what videobloging was before Youtube. I’m not saying that’s better, I still like watching on Youtube, but I’d love it if there was a “Watching List” similar to how Reading Lists work.
Online experiences are great, but I like offline too. Podcasting has shown us that offline is worth considering, that it’s beneficial to our lives. Let’s imagine a future where offline and online are complimentary.
-
Offline Pull Requests
programming workflows
Aside from being a phenomenal version control tool, git’s ability to work offline is one of it’s best features. This is especially true if you move around a lot, but even if you don’t, sometimes you just need to disconnect from the network, avoid distractions from things like social media and email, and do some heads down focussed development.
Once you’ve made some progress, it’s trivial to sync back up with the repository remotes. Pull in the changes since you were last online, merge with your code, resolve any conflicts, and push your changes back up to the remote. This is possible because when you clone a repository, you have an entire copy of the repository on your local machine.
This way of working is standard with the command line git tool. It’s how it was designed to work. Each developer has a complete copy and can work entirely independently. This worked really well for many open source projects, but as git hosting platforms emerged, they added new features. One of the most praised has been the Pull Request (PR). It’s become so central to modern development, that most developer workflows in some way revolve around them.
They are essentially a way to co-ordinate ongoing feature work. They take the form of a web page that has a discussion thread where contributors can talk about the changes they are making to the code. They make many code commits to a feature branch on their local machine, push those commits to the remote, and at some stage a PR is created. Discussions then happen, more code commits can be added, and when the feature is deemed to be complete, it can be merged into the main branch and the PR is closed. At that point all the commits that were pushed to the feature branch will be in the main branch.
The PR has become more that just a discussion area. Many integrations with 3rd party tools enable running of test suites, with results displayed in the PR page along side discussions. There are other neat features like bots that can scan code, and post results to the discussion, code reviews, analysis of comments to see mentions of other PRs, and for example to trigger workflows. The automation features can help speed up development, and maintenance of the project. Overtime PRs become a key place where knowledge about how the code was developed is stored. It’s very usual to spend some time browsing through closed PRs to get a sense for how things are moving along, or how a particular bug was fixed. The PR has been very much a successful feature and has been adopted by most git hosting services.
It’s not to say that PRs don’t have their downsides. Some of these were highlighted in a recent episode of the Changelog podcast(~20:00). They speak about many of the pros and cons. It’s an interesting discussion. There has also been a “PRs are bad” meme making the rounds the past few weeks (but I can’t find it right now), and much has been written about the pain of PRs. We love PRs, but some of us, at times, find them an impediment to progress.
In my personal work I often want to be able to work entirely offline, but I miss the ability to write notes as I develop a feature. There isn’t much point in using PRs since they aren’t accessible offline. PRs are entirely provided by the platform, standard git has no such feature. Making PRs available offline would be an incredible feature, but it probably doesn’t make that much sense, because the threaded discussions would get all out of sync. I’d be happy to be proved wrong on this though.
Offline PRs would make moving between providers feasible. If you have ever tried to do that you’ll know that it’s not at all straight forward. Moving the repo is easy, moving the PRs and all the accumulated knowledge within them, not at all easy.
However with PRs acting more and more as a place to combine the results of many tools, I wonder if there couldn’t be some form of independent notes that couldn’t be written offline that could then be automatically attached to a PR along with the pushed code commits.
If I were developing git based tools, enhancing the offline experience would be something I would spend some time on. Working async is becoming the norm for remote teams, and though it’s great to work together and essential at times, the ability to drop off and work offline is something that is very important in order to be able to keep a healthy work/life balance, but also so that when you do get together with the team, that time is even more beneficial because you’ve been able to make much progress offline, without all stepping on each other’s toes.
-
Exploring iOS Creation Tools
ios & mac operating systems design
I recently had to re-install most of the main Apple iOS apps as the previous versions were all crashing on startup. While I was doing this, I took some time to look at the feature sets of these apps, most of which I never use. I was pleasantly surprised, there’s actually quite a lot you can do with these default apps that look like it could be very useful. A lot if the apps are quite minimalist, and have enticing design.
However functionality is not obvious straight away. I find that most of these apps don’t seem to follow typical conventions for where features are or how they are implemented. Each one appears to do things in a sort of unique way. The first 20-30 mins of playing with an app, I was constantly taping the wrong place, opening the wrong menu items, getting stuck and having to close the app and re-open it just to get back to a place I recognised. It’s way too easy to delete things in iOS apps, and there’s no undo. I’ve lost / nearly lost loads and loads of stuff accidentally deleting something when the touch UI started miss-interpreting my gestures, or accidentally making an unintended gesture. So it’s not obvious and learning is very frustrating.
Having said that it looks like the following things might be possible with standard Apple apps:
- Publishing ebooks (Pages)
- Recording and editing audio (GarageBand, Voice Memos)
- Recording and editing video (iMovie)
- Some basic automation (Shortcuts)
Being able to do all these things from a mobile device would be awesome.
The design of these default apps have a very “Apple” look and feel to them which is great. However I’m a bit disappointed that documentation and marketing pages are a very scattered. The default selection of apps is actually quite good, but I don’t get the impression that Apple is taking them very seriously. Each one should have a canonical page on the website and there should be downloadable documentation. The whole offering feels more like a shabby patch work than a suite for creators. It’s like they did all the hard work of building the restaurant and then gave up right before creating the menus.
Anyway, in my experiments with GarageBand, though making music is probably a bit optimistic for me currently, recording an audio podcast might be possible. I’d like to be able to record audio segments and drop them into some form of template, and render out an episode, complete with intro and segment audio jingles.
I’m guessing the whole template thing probably isn’t possible, but having a rudimentary way to put together a podcast from some audio clips might be.
Speaking of which, wouldn’t it be awesome if you could add annotations in the Podcasts app while you were listening to a podcast, and a way to easily crop out short clips, so that you could insert them into a podcast you were creating?
I like the idea of being able to have an async conversation via the medium of podcasts, for fun but also could be very useful in a work setting too. Anyhow just wanted to mention briefly my recent experiences with iOS apps, frustrating, but I can see potential possibilities.
-
Nginx and the Ukraine-Russia war
programming open source
With the war in the Ukraine unfolding, I started wondering about tools and libraries that might be affected by the crisis. What happens to open source projects that are caught in the cross fire of war?
The first such item that sprung to mind was Nginx. It’s used by an enormous amount of the modern web as a reverse proxy and load balancer.
Nginx is one of the biggest open source successes in recent memory, and as far as I know it’s developed by russian based developers. Looking at their website it appears they self host all development rather than use a git SaaS platform like Github.
Nginx has already been in the news in the past couple of years for similar issues. Thankfully the code is open source, but it’s clear that developing safe and reliable software for a world wide ecosystem is not very straight forward.
With the US and many countries imposing sanctions on Russia, how will that affect the open source communities online?
I don’t have an answer to that question, but it’s something I’m looking out for.
My best wishes to both Ukrainian and Russian developers, I hope you aren’t caught up in the madness of war.
-
The Mirror (A poem of cruelty)
blogging writing poetry
They: Be the mirror!
I: I won’t be the mirror!
They: we hate that you won’t do what we say, so we hate you!
[some time passes]
[everybody is a bit sad]
They: what do we do?
I: I don’t know
…
[some time passes]
…
They: Be the mirror!
I: I’m the mirror!
They: we hate the mirror, so we hate you!
[some time passes]
[everybody is a bit sad]
They: what do we do?
I: I don’t know
…
[some more time passes]
…
I: I guess I’ll go then, again. Maybe some others have food that I can eat and water that I can drink, so that I don’t die
###
Update: This poem will be the last that I ever write so as to try to avoid even more abuse than is currentky beibg inflicted upon me. Cruelty should not be encouraged. Cruelty in the world is very real, I am absokutely certain if that now.
Update: Lots of very unnusual internet connectivity issues today
-
Next generation tools and workflows for the creator economy
blogging writing web development programming javascript
There was an Interesting Smashing Magazine piece earlier in the week, Thoughts On Markdown. It does a really good review of the transformative effect Markdown has had in tech, especially by developers, but also by creators.
Markdown unlocked a whole ecosystem of workflows, that have been generally centered around git version control platforms such as Github. Reason being that they now all offer CI/CD tools, i.e ways to run shell programs that can do things to and with the files in your repository when you do different actions like push/commit/merge files.
I wrote about this trend a little over a year ago in my piece about Github Actions for custom content workflows. I later wrote about Mozilla MDN Docs are going full Jamstack, which was a high profile example of the trend. I was seeing in my own work how the combination of automation, git version control and a simple authoring format were transformative in what I was able to do. I think the fact that Mozilla went all in on such a workflow is a big sign of things to come.
Along with the praise about the impact, the Smashing piece’s thesis is that although good things have come about because of markdown, that it isn’t well suited for editors, writers and creators. They go into a lot of depth in their article, it’s really worth the read.
I’m sympathetic to their point of view because although it’s fantastic for quickly writing documentation for coding projects, I have found it a bit tedious for writing, but especially editing essay style pieces.
I love how easy it is in Markdown to add URLs, lists, for boldening/italicising text, and for adding titles and sub headings. Guess what you can also just add HTML directly in the file for those situations where the syntax falls short. All that is great, and it doesn’t bother me that you end up with some slightly ugly syntax scattered through the text. I’m fine with that, in fact for URLs you get used to it very quickly, and it’s actually, in my opinion, argusbly better to be able to see the full URL text, so you can easily spot mistakes before publishing, and it encourages you to favour well written URLs. It’s often overlooked because it’s somewhat subtle, but structured and nicely formatted URLs make browsing and sharing on the web a much nicer experience.
The biggest annoyance for me is in the editing, because the way corrections are displayed in a Github PR are sort of close to unreadable. Each paragraph is one line in a markdown file, and if you change 1 word, the entire paragraph is highlighted in a way that you lose the flow of the whole document. I’m constantly having to preview, commit, review. It’s that feeling where you can’t see the woods for the trees, and it makes writing prose much more difficult than it should be.
The topic came up in a recent Shop Talk Show. Dave is keen on exploring Markdown editors when he’s old and Chris is bullish on block editors from his mostly very positive experience with Wordpress’s newish Gutenberg editor. He’s always going on about it (in a good way), so there must be something to it.
And that’s were the Smashing piece ends up, talking about the concept of block editors, which I am totally unfamiliar with. It sounds interesting, though I wonder how much of the automation and collaboration features of a Github+Markdown workflow you would lose by moving to block editors. Also, and this is a big one: portability. I personally am willing to put up with some of the annoyances of Markdown because, I know it works everywhere that supports git repos. Where is the portability in block editors?
There are signs that some of the benefits of modern webdev blocks and components are making their way into Markdown, with for example Mdx, which is a markdown variant that makes it possible to embed React and Vue components directly in your markdown files. So maybe we will get both markdown and block editing in the new embedable web that the folks at Smashing envision.
It’s a topic that I’m watching closely because it will have a big effect on what I like doing. I’ll finish with a Markdown Pro/Cons list as I currently see it:
Markdown Pros:
- Portability
- Collaboration
- Git friendly
- Compatibility
- Huge ecosystem of tools
- Being able to stick it in a PR, then stick it into a workflow
Markdown Cons:
- Not the best writing experience
- Lousy editing experience
-
Changes to the blog and newsletter
blogging web development linkblog programming javascript newsletter
Towards the end of last year, I stopped posting to the linkblog. It wasn’t by choice, I still enjoy reading and curating content, but life configured itself for me in such a way that it was basically impossible to do in any meaningful way. I had just reached the 10 year anniversary. I’m glad I made it that far, but the world said no, loud and clear.
I have no way to post privately using the linkblog tool. I never had the chance to build that feature. It was on the roadmap, but there were always more important features that popped up, and I had made the decision to implement that feature later to try to make things a bit easier. There was already so much to worry about, and it seemed to me that storing less private data would eliminate a whole class of security concerns for my little sass web application.
With no links, I didn’t have any material for the newsletter, so that had to be put on hold. I eventually did send out a short new year’s edition. It was fun putting it together, and to be honest I quite liked the brevity. I put out another, and another. I also started adding a short unique one line title to each edition. The idea was to have something memorable, a sort of virtual hook to hang it on, so it doesn’t just fade into obscurity of time. I’m liking the new format.
I also have a bit of a goal of writing more blog posts, but I want it to be fun, and not get too stuck in crafting the perfect post each time. I might check out some writing tools I keep hearing and readibg about like Grammerly and Hemingway at some point. Until then though I’m just going to try writing and editing quickly. So expect the posts to be a bit rough around the edges, with spelling mistakes, and annoying repeated bits. Sorry. Those bits annoy me too, but I think quantity and general narrative is more important than minutia at the minute. Hopefully my writing will get better over time. It’s a somewhat different way of thinking to writing code, and my brain just doesn’t do it all that well yet.
I’m still liking the idea of publishing on Saturday, but I’m going to be more flexible. I might sometimes do a week day issue, and I’m not commiting to every Saturday, life is too darn complicated at the minute. I’d love to have a consistent schedule, everyone says that’s the best way to increase readership, but it’s just not realistic for me right now. It’s the “if the world allows” attitude, I’m going to try but I’m not going to kill myself over it.
Ok that’s it, nothing Earth shattering but I’m feeling good about the changes. I hope you like the sound of them.
Update - Wow I just noticed how many 2s there are in today’s date. Hello world! 🤷♂️
TODO add links when world allows -
Component and configuration based UIs
blogging web development linkblog programming javascript
The past few days, following on from my investigations into the rendering process of modern javascript frameworks, I’ve had component and configuration based UIs on my mind. I’ve been wondering what the big deal is, why all the fuss, when it seems to just boil down to co-locating your templates and code together.
I kept thinking there must be more to it. But then I thought, what if that really is all there is to it, there are probably other reasons, but what if it is just about co-locating the templates and the code, would that be so bad?
One major annoyance with templating is making sure all the functions you are using in your templates are in the render context at render time. If any of them aren’t there, the rendering is going to bomb because the template library will do exactly as you have written in your template logic, except some of the functions you told the library to call just aren’t there, and when your template reaches one of those, it results in a runtime error. If you don’t use many functions in your templates, this is likely a non-issue. On the other hand if you do, then it is a pain you face.
The way it’s done with regular template rendering, is that you have to look down your entire template hierarchy, note down which functions get used, and pass these into the top level template, as part of the data object, and you have to make sure that each time you include a template/partial, to pass the right functions into the render method invocation for that template/partial. So again, if you don’t use many nested templates, it’s probably a non-issue. But if you do, then welcome to code bombsville.
For people that write highly nested, highly functioned templates, collocating code would perhaps be beneficial, just to make preparation of render contexts less error prone.
With all that in mind, I decided to just try adding component rendering to my ssg in a feature branch. Worst case is that it doesn’t work and I could just delete the feature branch.
I thought about it for a few hours, looking at my code, looking at javascript’s implementation of classes, which bundle functions, over and over again. It’s still very new code, so I wasn’t totally sure about it, but I think I could see a way to modify the ssg that would result in component rendering.
It was simple enough, just add a renderComponent method to the renderer, and that method would grab all the functions from the passed component, merge them into the data object, and pass that into the regular render method. Could it be that simple?
renderComponent(component, data) { // Add component functions to render context const templateBody = component.getTemplate(); const templateData = Object.assign({}, component.getData(), this.getComponentFns(component)); return this.render(templateBody, templateData); } getComponentFns(component) { return Object.getOwnPropertyNames(component) .reduce(function(acc, current) { acc[current] = component[current]; return acc; }, {}); }In the javascript community such implementations are often referred to as syntactic sugar. Might be the same in other language communities, I don’t know (update - turns out it is the same in other programming languages). Essentially the underlying process remains the same, but a new structure is available which is useful in many situations. Examples of this approach are Classes, syntactic sugar on top of prototype based inheritance, and Async/Await which still uses traditional callbacks underneath, but via promises.
It’s pretty clear to me that if you can write your template alongside the functions it uses, and be sure that at render time, all the functions will be available, then that’s a net positive. And it might very well be that there are other, more frontend centric reasons to use components.
Anyway, guess what, it worked!
It seems sort of obvious now, but sometimes when you are in the fog of technology, mental models, implementations, buzzwords, build tools, peoples opinions, and just the complexities, mutilations, humiliations, thirsts, hungers, dirtyness, impossible situations, contradictions, blocking, pain, starvation, cruelty and madness of life, it totally doesn’t seem obvious!
In the end I added about 10 lines of code, and a very simple Component class, and it worked, the component I included in my template rendered! And since my ssg has a way to define custom renderers, most libraries that support partials/includes should now be able to render components. It’s early days and I havent done much testing, but it seems as though it is possible.
It was quite a moment, when I ran the code, I sort of knew it would work, but it was still a pretty big wow moment. I was like, “wow it worked”. That doesn’t happen very often in programming, at least not at that scale.
Regular template rendering still works as before, and for templates that don’t use lots of functions, that’s probably going to be the better, simpler way to go. But if you do write templates that use lots of functions, using components is a neat way to bundle them with your template, so that at render time the functions are right there in the context, no need to do any special preparation.
The only current limitation is that your top level can’t be a component, it has to be a template. The ssg renders components inside templates. There might be a way to have top level components in the future, I haven’t figured out an easy way to do that yet.
One other thing, not related, but related, if there is one thing I have learnt here in Vietnam, it’s that the people are cruel, and their cruelty will only increase over time. This is my opinion that has been formed after living here several years. They aren’t all cruel, but when all is said snd done the net cruelty only increases. I really feel I have to say that now, while I still am able.
They should consider renaming it the People’s Cruelty of Vietnam. It would be a much more accurate description of the place.
-
What’s up with templating in modern javascript frameworks?
blogging web development linkblog programming javascript
I’ve been writing a static site generator recently. It’s a rewrite of a utility that I use to build my statically generated linkblog. That utility has been working well, but it’s implementation isn’t exactly very elegant. It was, after all, my first attempt at building the linkblog statically, which had previously been a typical MongoDB backed Express app.
I’ve been really delighted using many of the latest javascript features. Specifically Classes, Array functions (especially map and reduce) and Async/Await. That combination IMO has dramatically improved the development experience. The code is massively easier to reason about, and just looks so much better.
class Dispatcher { constructor(app, cfg, renderers, collections, srcDir, outputDir) { this.app = app; this.cfg = cfg; this.renderers = renderers; this.collections = collections; this.srcDir = srcDir; this.outputDir = outputDir; this.renderersByName = undefined; this.renderersByExt = undefined; this.outputPaths = []; } async init(templatePaths) { debug(`Initialising dispatcher with templatePaths: [${templatePaths}]`); // Arrange things for easy selection this.renderersByName = this.getRenderersByName(); this.renderersByExt = this.getRenderersByExt(); for (var i = 0; i < templatePaths.length; i++) { // ... do some rendering ... } } getRenderersByName() { const renderersByNameReducer = function(acc, current) { acc[current.name] = current; return acc; } return this.renderers.reduce(renderersByNameReducer, {}); } // ... }The latest ssg tool now has all the basic features I need to rebuild my linkblog. It uses what I call “old school templates” to render all the pages. In my case it’s EJS, but it could work equally well using any of the many other template libraries like handlebars, liquid, mustache etc. I wanted to get that working before venturing into rendering pages using some of the more “modern” component based javascript frameworks like React, View and Svelte.
This past week, I’ve been looking at these frameworks more closely, trying to figure out how the rendering works. I’m trying to get a sense of what modifications I’ll need to make to my ssg so that it can generate component based websites. I’ve read so much about these frameworks over the years, it all sounds so wonderful, but also quite mysterious.
With old school templating rendered server-side, though there are lots of peripheral features, it essentially boils down to passing a template string together with an object containing data to the templating library. The library takes the data and the template string and gives you back an HTML string, a.k.a the rendered page. You write that to a file. Rinse and repeat, upload all the files to your CDN / hosting provider, and that’s your site live.
debug('Renderer fn - ejs: rendering template'); const renderedContent = ejs.render( templateBody, context, options ); return renderedContent;The template libraries have lots of neat features to make it easier to create your pages. One such feature is the ability to include templates inside templates. You create templates for small pieces that you can reuse across all your pages. On my Jekyll based blog for example, I have among others, includes for the Google analytics snippet, as well as messages promoting my development services that appear on each page. I can update the included templates and the messages update across all the pages that use those templates. The feature is sometimes called partials, it’s been a standard feature of ssg’s for many years. Each library has a syntax for describing the include that you insert directly into the template HTML, and you often additionally pass the include a data object which is used by the library to render the included template.
<h1>Hello World!</h1> <h2>Some included content:</h2> <%- render(includes.helloIncludes, locals) %> <h2>Some regular content:</h2> <p><%= locals.loremipsum.content1 %></p>It’s worth noting that in most implementations you can pass functions in the data object, and use those functions directly in your templates. The libraries execute these functions as part of the rendering of the page.
The templates contain the logic for creating the HTML files, your javascript code which you use to fetch and prepare template data is in separate files. What about the modern frameworks, what are they doing?
Well there’s a lot of buzzwords and fancy sounding terminology, but after reviewing several component based projects, it seems to me they are doing essentially the same thing, except the template code has been moved into the javascript files inside a return statement, components are essentially the same thing as includes, and even props, which is one of the key concepts are really just the same as the data object that you pass to includes. All this mystery, and really it’s just another template library. I’m probably missing some crucial detail, but after a few days of digging, that’s what I’m seeing.
class ShoppingList extends React.Component { render() { return ( <div className="shopping-list"> <h1>Shopping List for {this.props.name}</h1> <ul> <li>Instagram</li> <li>WhatsApp</li> <li>Oculus</li> </ul> </div> ); } } // Example usage: <ShoppingList name="Mark" />There must be something else that’s useful over and above collocating related code together. At the present moment I personally find that sloping everything together causes me more confusion, because it’s difficult to conceptualise where the boundaries of the app are located. It’s just this vast amorphous everything code, instead of code that’s divided into rendering logic and data preparation logic.
I’m aware that I’m coming at this from a very server-side way of thinking about things, and probably component based websites make a lot more sense once they are running in a browser environment, with event handlers and the like, but nonetheless, I find these observations interesting, even if no one else does.
What’s the major advantage that you get from sticking the template into the javascript?
-
Static site generator development continues...
blogging web development linkblog programming
Here are the notes I mentioned in my previous post. You’ll get some idea of what I’ve been up to in my personal development projects, even if it’s not a nicely crafted piece, I’ve made some progress on my static site generator, and I wanted to blog about it. Still blogging… :)
- Initial version which I wrote as a sort of life raft when the linkblog.io ship was sinking
- Jamstack, serverless, Netlify, Github Actions, CI/CD, and git repo powered development were all becoming super popular
- It’s running my current linkblog, it works, it’s all running in the cloud, quite awesome
- But…the code is kind of fragile
- quite a lot of duck tape
- the structure of the code is convoluted in places
- lots of callback hell
- hey async/await was new when I wrote it and I hadn’t gotten comfortable with it yet
- It uses plain javascript objects rather than classes, which is mostly fine, but I’ve seen quite a few implementations of tools that use classes
- it’s much clearer to me now how to think about and mentally manipulate such concepts
- there’s a lot of flexibility and structural benefits when you have the right abstractions
- you can more easily get out of the weeds in some places
- You can more easily build something that can be refactored to suit your current needs
- Classes do present a new set of challenges though, but on balance, I feel like they are the right structure to be using a lot of the time
- I wrote an initial version back before the big lockdown happened, I had been thinking about it for a while and was able to get something working over a few days
- The main ideas were
- Just render templates, stick to EJS and Markdown, keep it simple
- Path base page routing
- Maybe rendering websites using templates could be similarish to how a render farm operates, something I have a lot of experience from my time in the feature film visual effects (VFX) industry
- I had been reading a lot about various more formal data structures, and it was clear to me that a queue would be beneficial to handle all the template rendering
- Just get something working that runs locally, but maybe if the architecture was done right it would be easy to get things working in a serverless environment later
- Initial specific requirements for phase 1 - Implemented these crucial examples very early, and so can easily check that structural changes don’t break these
- EJS using data files
- EJS with includes
- Markdown
- Phase 2 implemented after the big lockdown, once again I’d been thinking about the best structure for many weeks and was able to get these changes made over 3-4 days
- A set of core components have emerged that feel really nice, a structurally sound way to render templates, with possibility to extend functionality
- Things I have in the back of my mind
- How to handle config
- How to handle more advanced template rendering, for instance how to render many different output pages from a single template, with some kind of iteration logic, necessary for rendering the linkblog calendar folder structure
- Concentrate on EJS, but try to architect a solution where different ways of rendering templates could be accommodated in future, at least try to go in that vague direction even if it’s not a completely working multi-rendering solution at first
- Create the right abstractions so that changing template rendering input and output locations is trivial (i.e. local file system, S3 like cloud storage etc)
- Inspiration
- Jekyll - the ssg I currently use for my blog
- Eleventy - awesome ssg that uses classes in a really nice way, great community
- Pixar’s Renderman - the standard for running large scale render farms in the VFX industry
- Render farms - [memories I have of my time working with VFX render farms, mostly sysadmin/devops stuff, but also some of software development
- Serverless and Jamstack the shiney future at the end of the tunnel
- Wordpress, & open source
- Open source
- Something I’ve wanted to do for many many years
- There’s been a lot of Linux in all my previous jobs, I feel like I’ve been living and breathing in open source in one way or another all throughout my career
- But I must mention though that the closer I get to having something that I feel is good enough to ship, the more ham strung and hands tied behind my back the world around me has me feeling, not so great considering the whole point of open source
- Which license to choose, MIT, GPL or Apache, or something else
- How to handle the competing, often contradictory aspects of the intersection between developing software in the open, and having a balanced personal life
- Somewhat esoteric, feels like I should mention, without dwelling on them for too long at this point in time
- Why does it feel like the choice of open source license somehow impacts the freedoms I experience in my personal life?
- Why does it always feel like right after I do one of these 3-4 days development sprints on a personal project, that I get absolutely clobbered by the world around me? It’s like clockwork, happens every single time, I’m not particularly religious, but is this the metaverse of the future, appearing in the present? Seriously, it really worries me, and especially that it’s impossible to talk about without sounding like you’ve lost your marbles
- The try to stay alive cascade
- survival
- self-preservation
- try not to negatively affect others
-
Hi it’s me. I’m still alive.
blogging web development linkblog programming
I just wanted to say hi and wish a happy new year to all.
The world is pretty complicated for me at the minute, I ended up in some sort of metaphorical/metaphysical (but in a lot of ways, very real) alive/dead loop in my life, so I just stopped posting because I sensed that it was going to continue for a while, and the thought of what that would look like from the outside had me thinking “No thank you very much”.
I’ve done some development on my linkblog ssg, and I’ve just written up some notes.
Hopefully it will turn into a blog post, though I think I’m just going to post the unedited bullet points rather than turn it into a beautiful written article. That’s all the world is allowing for me at the minute, but I want to put something out there, because life goes on even if it’s difficult sometimes.
So once again, happy new year, best wishes for 2022.
-
My javascript / tech / web development newsletter for 2021-08-14 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-14-08-2021-take2
-
My javascript / tech / web development newsletter for 2021-08-07 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-07-08-2021
-
My javascript / tech / web development newsletter for 2021-07-31 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-31-07-2021
-
My javascript / tech / web development newsletter for 2021-07-24 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-24-07-2021
-
My javascript / tech / web development newsletter for 2021-07-17 is out!
newsletter
In this week’s edition:
Creativity and optimism in tech, general webdev chat, javascript engine implementors
https://markjgsmith.substack.com/p/mark-smiths-newsletter-17-07-2021
-
My javascript / tech / web development newsletter for 2021-07-10 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-10-07-2021
-
My javascript / tech / web development newsletter for 2021-07-03 is out!
newsletter
In this week’s edition:
Instagram more than just photos, AI tools for developers
https://markjgsmith.substack.com/p/mark-smiths-newsletter-03-07-2021
-
My javascript / tech / web development newsletter for 2021-06-26 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-26-06-2021
-
My javascript / tech / web development newsletter for 2021-06-19 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-19-06-2021
-
My javascript / tech / web development newsletter for 2021-06-05 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-05-06-2021
-
My javascript / tech / web development newsletter for 2021-05-29 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-29-05-2021
-
My javascript / tech / web development newsletter for 2021-05-22 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-22-05-2021
-
My javascript / tech / web development newsletter for 2021-05-15 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-15-05-2021
-
My javascript / tech / web development newsletter for 2021-05-08 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-08-05-08
-
My javascript / tech / web development newsletter for 2021-05-01 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-01-05-2021
-
My javascript / tech / web development newsletter for 2021-04-24 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-24-04-2021
-
My javascript / tech / web development newsletter for 2021-04-17 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-17-04-2021
-
The Reddit Account Saga
social media
I have been a reader of Reddit for many years but hadn’t until late last year posted anything.
I created my Reddit account sometime back in November 2020. 153 days ago according to my profile page. In my first post, I shared a link to a blog post I wrote about Robust NodeJS architectures. 138 days ago I posted a link to my newsletter in r/javascript and received a private message that it had been removed because it didn’t follow the subreddit guidelines.
Some time went by and I noticed that my account page appeared strangely when I was logged out. At times it showed a 404 page but other times it rendered a page where my username was replaced with the string ‘undefined’. I figured it was a bug in the rendering of the page, and kept using the account, everything else seemed fine. I could log in, read threads and post to subreddits.
I continued to occasionally post links to my newsletter, and mostly it was fine though I did receive one other take down notice. I eventually emailed Reddit support several times to ask them about the account, but only ever received automated replies that didn’t solve the problem. It really felt like I was being disappeared, because at this point I started to suspect that none of my posts were being seen by other users.
I posted on Indie Hackers to ask for advice. I also posted to some help subreddits. It was a landslide diagnosis: I had been shadow banned for posting too many links to my own content. In the process received quite a lot of criticism about how I was posting on Reddit, but also on other sites like Indie Hackers and Hacker News.
It was quite a blow, I had been sharing my newsletter that I spend many hours every week preparing, and just received criticism in return.
This wasn’t helped by the fact that the support team wouldn’t answer my emails aside from auto replies. I tried posting to a special subreddit that tells you if your account is banned, but it just didn’t reply anything. People seemed to think this was because I was banned.
In a separate Indue Hackers thread I had received some advice that Reddit was a good place to look for jobs, but I still couldn’t post. Eventually I decided to post publicly on Twitter and try to get the attention of the Reddit support team. The post never showed up in my timeline, and the only way I found to get it to show-up was to pin it to my Twitter main page. I ended up creating a Twitter thread to chronicle the things I had tried.
I never received any replies from the support team. Meanwhile my Twitter profile now had a strange Twitter thread attached to it that every job prospect was now reading. Not the best kind of look when you are looking for work.
Looking at the timeline of events, it still wasn’t obvious to me that my account was banned, because it would have had to be banned since before I ever posted anything, which doesn’t make any sense.
At some stage I found another Reddit page where you can request that your banned account is re-instated, so I went ahead and filled out the form. After submitting it, the page showed a popup saying that the account was NOT banned.
I emailed support yet again and this time got a human reply. A few emails later they informed me that my account had been caught in a spam filter, and that the issue had been fixed. I never received any notice from them that this had happened. The account finally started working many months after the issue first appeared.
Shortly after I posted to a jobs subreddit, my post was immediately removed and I was given conflicting information. I posted again on Indie Hackers to ask for advice. Basically one message said ask the mods, and another said that if I asked the mods I could be banned. I opted to just not use Reddit for job search, and I’ve mostly stopped posting to other subreddits.
It was a really horrible and drawn out situation that affected my life in many ways, where I was tried, judged, convicted and hung out to dry by the community, where there was no recourse, no procedures to restore my account. It’s really tarnished how I view community and the web. I’ve since had account issues with several other sites, including Freelancer.com, Coinbase.com, big named sites where you would expect account issues not to happen.
There were a few folks on Indie Hackers that helped and talked to me, interacted on some of my other posts, giving me good advice about my blog, and I’m great-full for their support during very difficult times.
I’m not out of the woods yet, but I will at least be removing the pinned thread from my Twitter main page later today.
Here’s hoping 2021 starts to get a bit better, even though the rainy season started a few days ago! There’s nothing better than rain thunder and lightning to remind yourself that you are still alive :)
-
My javascript / tech / web development newsletter for 2021-04-10 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-10-04-2021
-
Experiments with the newsletter structure and content
newsletter javascript web development linkblog
In the last few newsletters I have been experimenting with the structure and content quite a bit. The result is a much better newsletter that is easier to parse, where it’s easier to find interesting content, and where it’s possible to see the context around individual links.
My newsletter is evolving, slowly but surely, things are starting to take shape.
The current newsletter structure:
- Intro
- News
- Tutorials
- Technologies
- Write-ups
- Special mentions
- The best links from the linkblog’s last 7 days
- Footer
The last 2 editions have been particularly strong, with a focus on the news section, which is further subdivided into the latest trends, and changes week to week based on what I’ve been seeing.
Last week for example the trends were Congressional Hearing, Social Media Features, Chips, NFT and crypto currencies getting real, Other Bits and Pieces. These were different to the week before, but there is some similarity, because the topics developed and evolved.
The other sections are re-occurring and a way to more quickly find content you might be interested in. These categories seem to cover most things, but they might change a bit in the future. There’s structure but I’m not going to be militant about it and will add / remove sections as needed.
Navigating through a massive link dump is tedious, so the intro section aims to be a sort of meta index, to make it a more pleasant experience finding articles to read. It vaguely mirrors what was going on in my head when I found and posted the link, though that evolves throughout the week, culminating in a synthesising of the topics and trends.
Generally I’ve been very happy with the news narratives that emerged and also with the sprinkling of interesting javascript, technology and web development articles. I’m still working on getting the balance right, but I’m into the new format.
The other thing I’ve been experimenting with is to use linkblog hash links in the intro section. The idea here is that I want to somehow make accessible the context around a linkblog link, hopefully over time you’ll get a better sense for how the narratives emerged.
Since I choose all the links and write the copy, I have a lot of editorial control, but you can see the reasoning and source material behind a particular narrative and so you can more easily judge for yourself what to think on a particular topic.
Something that has been mentioned is the ‘double jump’, i.e. you have to click twice to get to the article: once to get to the linkblog link and then again to get to the actual article. It’s a little unusual, and there might be a better way to make the context available and have a way to get to the article more quickly. Who knows, it might even become ‘the thing’ that sets it apart from other newsletters.
Another aspect I experimented with in February was a Javascript Core Special Edition. That was a fun edition to put together.
As for the future, I’ve really been enjoying Twitter Tweet Threads recently, IMO it’s one of the platforms best features. I want a similar feature! :)
I’ve been pondering how to update the linkblog to create something similar, a way to group a collection of linkblog links on a timeline. I’ve got some ideas of how this could enhance the newsletter. There are a couple of wrinkles still to iron out, but that might be happening sometime in the future.
The newsletter is a work in progress, I’d love to hear your thoughts and suggestions via email or in social media comments.
- Intro
-
The evolution of my javascript, technology and web development newsletter
javascript web development linkblog programming
I started the newsletter back in November 2020, and I’ve published an edition every week since. That’s 21 editions so far!
In the beginning, I would extract the best links from the linkblog, prepend them with a short single paragraph intro section, usually a bit about what I had been up to that week, and that was it.
However It was apparent to me that 20-30 links in an email was quite a lot to parse through, so to draw attention to some of the links that had made an impression on me that week, I started to link to them from the intro. This worked well, though over time, the collection of links grew in size, and so did the intro section.
Eventually, though the content remained high quality, the intro section became a bit unwieldy in length and had a ‘wall of text’ problem. Readers commented that it was difficult to parse and find the content they were interested in. Since the intro was turning into a sort of meta index to the links, I added some subheadings, a few re-occurring ones and a news section that changes based on the latest trends.
Ideally I would link internally from the intro section to the relevant link further down the page, but Substack doesn’t yet have a way to do internal linking. I contacted their support to ask if it was possible, they have passed on the suggestion to the product team.
In the interim all the intro links are to the relevant post on the linkblog, which contains any comments I made when I posted it, and the link to the article. By looking at the surrounding links you can also get a sense for the ‘context’ when that link was posted.
It’s a work in progress, I’d love to hear your thoughts and suggestions via email or in social media comments.
-
My javascript / tech / web development newsletter for 2021-04-03 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-03-04-2021
-
My javascript / tech / web development newsletter for 2021-03-27 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-27-03-2021
-
My javascript / tech / web development newsletter for 2021-03-20 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-20-03-2021
-
My javascript / tech / web development newsletter for 2021-03-13 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-13-03-2021
-
My javascript / tech / web development newsletter for 2021-03-06 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-06-03-2021
-
My javascript / tech / web development newsletter for 2021-02-27 is out! Javascript Core Special Edition! 💯
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-27-02-2021
-
My javascript / tech / web development newsletter for 2021-02-20 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-20-02-2021
-
My approach to software planning and estimation
web development services programming freelance
While there isn’t a single approach that works for all projects, doing some planning and estimation goes a long way to increasing the chances of a successful project. I wanted to give my general approach and share some useful resources on the subject.
Here’s the general approach I’m going to take in this blog post:
Why planning and estimation
For smaller projects, a high level overview and a few diagrams might suffice, but for longer projects with more unknowns, it’s important to take more time, filling out a more detailed plan before commencing. At the same time you want to avoid getting stuck in endless details or a plan that isn’t flexible to changing conditions.
Identifying problematic areas, and finding an appropriate balance between planning and implementation is key, with good communication between the people involved in the project.
Create a high level system design
- Overview
- Project parts
- Architecture
- Issues / items that need to be discussed and solved
See the Facebook architecture planning videos for some good examples of high level system design:
- Top Facebook System Design Interview Questions (Part 1)
- Top Facebook System Design Interview Questions (Part 2)
Create a sprint plan
General approach is agile scrum methodology. Break down the project parts into subtasks (called stories), add time to each, gather all these into a backlog. These will be completed during time blocks called sprints, which last a set amount of time (typically 1 or 2 weeks).
During sprint planning assign stories to be completed in each sprint:
- high level sprint planning for several months at a time, and
- more detailed sprint plan each week for the next sprint
In pseudocode:
Take each project part - Create stories - Add story estimates - amount - confidence - measured - accuracy - Add stories to backlog - Total all the estimate amounts - Update measured & accuracy throughout projectThe following project planning article goes into a lot more depth on the subject:
Useful tools
There are lots of great agile development tools available, many of which have excellent collaboration features. You should probably use the best available at the time your project is happening.
Planning is such an important aspect of web development that I have build an agile blog tool that you can use just in case there’s nothing else available.
It’s open source, uses text files as storage, very unlikely to break, and will enable you to manage a backlog of tasks.
-
Hash links for individual linkblog items
web development linkblog programming
If you read the linkblog you might have noticed a change today.
The linkblog, by the way is where I share links I find online, it’s published every day at midnight.
Sometimes I add a bit of commentary, other times it’s just the link and page title. It’s mostly links to javascript, technology and web development content, but there’s often other stuff in there too. There’s an RSS feed.
At the end of the week I do a roundup of the best links and send it out in the newsletter.
One of the features that I lost when migrating from the old linkblog SaaS (which is sadly no more) to the statically generated serverless linkblog, was the ability to link directly to an item in a day. I’ve added this feature back, so you should see hash links next to each item in the linkblog. The day hash links remain unchanged.
The item hash links point to the archives rather than on the main page, because the main page only shows the previous 50 days, so it makes more sense to link to the archives, so that the link continues to point to something even after the item drops out of the most recent 50 days.
The feature is a little different to the SaaS version, it’s less fancy, but since it just uses a standard url hash fragment it works without javascript, which makes it arguably more robust.
It’s definitely useful, I’ve been experimenting with inserting linkblog items into blog posts as quotes, and having a direct link to an item will make that a lot easier.
Hash links are standard these days, quite well understood by users, people are used to seeing them on blogs and social media sites. I’ve also chosen a font size, weight and color that blends quite well with the page without getting in the way of the reading experience.
Though they add quite a lot of extra characters to the UI, I think on balance the page still has the minimalist aesthetic.
That’s the change, it’s nothing earth shattering, but the main linkblog page doesn’t change very often so I wanted to describe the change. I think you’ll find it a useful feature.
-
My javascript / tech / web development newsletter for 2021-02-13 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-13-02-2021
-
My javascript / tech / web development newsletter for 2021-02-06 is out!
newsletter
In this week’s edition:
https://markjgsmith.substack.com/p/mark-smiths-newsletter-06-02-2021
-
Cloud Native web application development: what's it all about?
web development nodejs architecture infrastructure cloud programming
I’ve been reading and listening to a lot of content related to Cloud Native web applications recently, so I wanted to gather together some thoughts and links related to the topic.
I previously built a robust NodeJS SaaS application, a Serverless Books API and some Jamstack Architecture Content Sites, so I have experience in both conventional and cloud based web application programming.
A lot of these technologies and paradigms are still somewhat in flux, but I think it’s worth adding my perspective to the conversation.
Here’s the general approach I’m going to take in this blog post:
I’ll also be adding in relevant posts from my linkblog. That’s where I’ve been gathering links. There will be a link to that place in the linkblog so you can see the context around that link, in case you are interested, and also a link to the linked article. Those bits will appear as quotes and look like this:
From my linkblog 12-01-2021:
Lenovo unveils ThinkReality A3 smartglasses with Snapdragon XR1 - This makes me wonder is VFX artists are going to be really into AR tech, especially all the 3D folks neowin.net
That’s the very latest link on my linkblog as I write this, it doesn’t have anything todo with this article, it’s just an example to show you what those bits will look like.
Hopefully by the end you’ll have a better sense of where this trend is heading and thus a better idea of what the future of web applications could look like.
The Cloud Native trend
History
One of the big developer trends for 2021 is the move to Cloud Native applications. Historically applications have been built to run on standard Virtual Private Servers (VPS) hosting, often running a flavour of Linux. This was a step up from having to run applications on bare metal servers, adding flexibility and decreased costs.
Over the past 10 years hosting providers have expanded their product catalogue from VPS hosting to offering a huge variety of services which can be integrated relatively easily into your application over the internet via APIs.
Another related trend in web development has been the resurgence of statically generated sites that make extensive use of APIs to carry out backend tasks. That trend is called the Jamstack, which is a broad term to describe websites that make use of javascript, APIs and markup to create sites that are performant, scalable and very secure. Providers like Netlify and Vercel offer file hosting packages bundled with serverless functions, making it possible to build websites without the need for classic VPS hosting.
Overall the move to the cloud has been gradual. When Amazon released S3 it’s simple file storage offering, it wasn’t at all obvious to most where the industry was heading. At the time, I was working in the visual effects industry at a company where all our tech was hosted on-premises. That was the norm, especially in post production. The idea that you would store files over the internet just didn’t seem realistic. There certainly wasn’t a general awareness of the explosion in APIs that was about to happen.
The technologies improved, and in recent years there has been broad adoption of cloud technologies across all industries, with application developers modifying their applications to offload certain tasks to these cloud based services. Amazon is the biggest player and has services such as DynamoDB (database), S3 (file storage), Route53 (DNS), Lambda (event driven serverless compute), SNS (notifications) and SQS (message queuing) to name a few. Other large hosting providers such as Microsoft Azure, Google App Engine, aswell as smaller ones such as Linode and Digital Ocean have similar offerings. These services provide highly available and effortlessly scalable solutions to common computing problems.
Cloud Native is the logical conclusion of this gradual move, with applications being designed and implemented to run completely on cloud services.
From my linkblog 31/12/2020:
Software Engineering Podcast - Cloud-Native Applications with Cornelia Davis (Repeat) - Looks at applications architected and built to run exclusively in cloud environments, covers event driven architectures, functional programming, infrastructure as code, Kubernetes, immutability and workloads, cloud failure domains, statelessness, microservices vs monoliths, and the new cloud abstractions such as Lambda and Big Query softwareengineeringdaily.com
Benefits
There are several drivers of this move to Cloud Native applications.
A big one is cost. These hosting providers are running their operations at such scale that they can offer very competitive pricing. For example in 2019 Amazon AWS data centres covered 14 million square feet. They have continued to invest in both hardware and specialist virtualisation software lowering costs and increasing utilisation, and those cost savings have been passed in to customers.
Related to cost is the move to usage based billing. Whereas with VPS hosting you had to at least pay for an entire server running 24/7, with cloud computing you can pay for exactly what you use. Each service is billed in slightly different ways depending on where the cost is associated. You can for example pay for exactly the storage in GBytes you are using, exactly the volume of inbound and outbound data in Gbits you are transferring, and exactly the number of requests you are making to a service. The services pricing are usually divided up into tiers, and often include a free tier for low volume usage.
It’s a model that has grown very popular with developers as it can accommodate for large variability in load. Whereas in the past it would have been necessary to manage a lot of infrastructure, all that complexity is handled by the hosting provider. And their infrastructure is the best in town, since they’ve been developing it for many years. It’s as if you had your own highly available, infinitely scalable, robust and flexible infrastructure. It’s possible to build Cloud Native applications very rapidly. You are quite literally building on the shoulders of giants in the industry.
Amazon is investing heavily this vision of the future of computing, recently announcing it plans to train 29 million people for free on cloud computing over the next few years.
Challenges
With all this progress it’s important to step back every once and a while to assess the situation. How resilient and robust is Cloud Native really? Let’s look at some areas that should be considered.
Well from a technology perspective it is undoubtably very resilient and robust. Most of these platforms are at the stage where a lot of the technologies have been operational for many years, supporting customers from a wide range of industries. They have been fine tuned and battle tested, and as a result are some of the best technology stacks available.
One technology area that I feel still needs improvement is the developer experience. Since all the services that you are using are cloud based, it becomes a bit of a challenge setting up local developer environments. There are tools and libraries available to create local versions of the services that you are using. For example Amazon has the Serverless Application Model and the aws-sam-cli, similar developer tools exist for other providers, but there isn’t a whole lot of standardisation, so this area can be a bit confusing. I expect the tooling to improve over time.
Some libraries and frameworks I’ve found useful for serverless development:
serverless-http - Wraps your entire server framework so you can use it in a lambda function, supports a load of server frameworks including express, koa, hapi, fastify and restify. Useful for creating apps that can run locally and in a serverless function.
netlify-cli - CLI tool for interacting with the Netlify API, great for deploying to Netlify when you aren’t building your site on their infrastructure.
netlify-lambda - CLI tool for building and running your Netlify functions locally.
serverless framework - A CLI and web tool to build and deploy serverless architectures, includes supports for Amazon, Azure, Google among others. Makes it easy to configure and provision all the components of your Cloud Native application.
Another area to consider is long term costs. So far we have seen costs mostly getting cheaper, but that might not always be the case, it’s still relatively early days for the cloud industry as a whole. One example where costs suddenly went the other way is Google Maps. Back in 2018 they raised prices by ~1,400% overnight. Application developers were not happy, but it still happened. Price hikes have happened in the past and will likely happen again somewhere in the future.
Also it’s worth noting that the pricing structure can have a direct effect on your business that isn’t always obvious. Engineers might start to carry out their duties in a different, non-expected, non-optimal way in order to avoid hitting different pricing tiers. These effects can be difficult to uncover.
From my linkblog 13/12/2020:
The author explores the landscape of buy vs build in detail, lots of food for thought, the arguments for building are generally much stronger when it’s a solution that solves something that is core to the business - I’m linking to the HN thread because there are some interesting comments about how vendor pricing models can effect growth in ways that aren’t immediately obvious ycombinator.com.
As is always the case with the tech industry, there will be mergers and acquisitions, that is a certainty. When that happens there are large shifts in power dynamics throughout the industry. The next 10 years are going to see some big changes throughout the stack with activity already happening right at the hardware level with a move from x86 to ARM chip architectures, most notably with the recent announcement of Apple’s M1 chips.
From my linkblog 21/12/2020:
Apple M1 foreshadows Rise of RISC-V - Another piece about the future of chip architectures, it appears like a general move towards ARM cpus surrounded by specialised corprocessors running RISC-V with special extensions to the base instruction set, also discusses the possibility of using RISC-V for the cpu medium.com
That’s a massive change, and it’s not just for consumer hardware either. There are plans to have M1 chips running in data centres to take advantage of their much lower power to watt ratio, and their new architecture that is very well suited to AI compute tasks. Shifts such as Nvidia attempting to buy Arm are going to continue and their effect will be felt throughout the industry.
From my linkblog 02/12/2920:
Amazon unveils 5 new EC2 instance types, the most interesting being the Amazon-made Graviton2 powered instances for compute heavy applications which uses the ARM chip architecture, can deliver a whopping 100 Gbps network speeds at 40% price performance over existing Intel x86 chip architectures - Lots of movement in the chip architecture space at the minute zdnet.com.
Also worth considering: The forces of government have been stirred in recent years, with the introduction of new rules and regulations for technology companies, especially in the EU with legislation for GDPR, EU’s Article 11 & Article 13, and Section 230 to name but a few. Similar legislation is being drafted in countries all around the world. How these will play out is unknown at this time, but as some of these regulations get passed, there will be pressure on hosting providers to enforce new rules, and that could affect some hosting provider customers.
Cloud Native architectures are technologically robust, and will enable you to get up and running quickly, but there are aspects of the bigger picture that are worth being aware of. It will be crucial to be ready to pivot if necessary, know where your cost centres are, and perhaps consider building some infrastructure that would enable a move in a worst case scenario event.
Alternatives
Infrastructure
One of the biggest developments in the recent past when it comes to infrastructure is Kubernetes. It was originally written by Google for managing its data centres, and is now open source and maintained by the Cloud Native Computing Foundation. It is a platform for automating deployment, scaling, and operations of application containers across clusters of hosts.
Containers can be thought of as slimmed down versions of VPS hosts that instead of containing an entire operating system, only contain exactly the operating system pieces that your application requires. With Kubernetes it’s easy to create and configure the resources your application depends on, deploy the latest application code, and ensure that your application is distributed in such as way that it is always available. It automatically does a lot of the heavy lifting that is necessary when you are running on standard VPS hosting.
Relevant: Software Engineering Podcast - Kubernetes vs. Serverless with Matt Ward (Repeat)
An interesting aspect is that since Kubernetes is open source and platform agnostic, we are starting to see offerings from all the major services providers. What this means is that if you do need to move between providers it’s a lot easier since the application will run on any Kubernetes cluster, regardless of provider.
As well as the ability to move, we are starting to see companies investing into building multi-cloud infrastructure. Software such as Cloud Manager, makes it possible for your application to run seamlessly across hosting providers. There will likely be a lot of development in this area as more and more companies seek to build out resilient and robust infrastructure.
Software Architectures
Whether you have opted for a classic VPS style infrastructure or the more modern Kubernetes based infrastructure, the question of how best to architect your application will come up. In the early days it’s often best to keep things simple, have minimal layers, use just enough code to get the task complete. You will be learning about the intricacies of your problem domain and having too much code can get in the way.
Once you start integrating a few cloud services though, and especially if you want the ability to easily switch providers you will want to architect your application in such a way that makes it easier to do that.
A popular way to do just that is to use Domain Driven Design techniques, an example of this is Microservices Clean Architecture Patterns. This approach uses entities, controllers, adapters and frameworks/devices layers, resulting in an architecture where changing the elements in the outer layers is much easier because you mostly just need to create new adapters, while much of the core business logic will remain unchanged.
I have had good results using some of these techniques in my Serverless Books API application. In my case the layers are named slightly differently, with handlers, utilities and adapter layers, but the idea is the same. Each layer encapsulates some bits of information so that the core handler functions don’t need to know exactly how the storage has been implemented.
The core layer handler functions use the addBook, getBook, getAllBooks, updateBook and deleteBook utility functions, passing in the query data, but don’t know any details about how and where the data is stored.
The utility functions, which are the next level out, know only the name of a table passed in via an environment variable. They use the create, get, getAll, delete and update db adapter functions passing in the query data and the table name.
The db adapter functions connect to the backend cloud database to perform the operation, do any necessary post processing to the data and return it through the layers back to the core, which eventually sends the data back to the end user.
Since the db adapter is generic it can be used by any utility function to read and write data to any database table, as long as the utility function passes in the table name.
Changing to a service hosted by another provider is then just a question of implementing a new adapter, the business logic in the core should remain unchanged, and only the storage identifier (i.e. the table name) might have to be updated to work with the new adapter.
Thinking about it logically, the most resilient way to develop applications in this way would be to always start by implementing a version of the service yourself, even if it’s paired down in functionality and scale, and only when you have a basic version running, write an adapter for the hosting provider’s version of the service. That way in the worst case you always have something to fall back on, though there would be some degradation to the performance.
Everyone’s situation is different though, and your circumstances might be such that you don’t have time to go through ultra-cautious route, in which case build out cloud integrations first, and at a later date back track and build your own fallback version of the service. There might even be cases where that approach is quicker overall because you will likely learn a lot about how to build yours by using that of the cloud provider.
Wrapping Up
Although it’s early days for cloud computing, even large companies such as the British Broadcasting Company (BBC) in the UK are building huge cloud native infrastructures. It’s interesting to read their high level goals and see how cloud technologies align very well with their mission.
From my linkblog 03/01/2021:
Moving BBC Online to the cloud - The engineering team writeup of their recent move from on-premises infrastructure to mostly cloud based where they are using serverless technologies extensively - Very clear articulation of the project high level goals, a description of the layered approach that enables code re-use but also keeps the flexibility to create custom specialised solutions, the re-organisation into teams focussed on page types and common concerns such as development methodology and hosting, interspersed with lots of development principles and guidelines - I have worked on several big projects at the BBC, it’s a staggeringly large organisation, so I am aware of how massive an undertaking this re-architecting of their infrastructure must have been, kudos to all the teams that made it happen medium.com
However remember they are a very big company, so they will have high leverage with their hosting providers and it’s likely that they will have service level agreements giving them preferred access to the hosting provider’s support staff. And of course they might very well be busy building their own fallback services too. Just because large companies go full cloud doesn’t necessarily mean that it’s the right choice for every business, the trade-offs and peculiarities to consider in the decision making process are going to be different in each situation.
Cloud Native is a tremendous leap forward for building applications. You will be able to rapidly build out applications that are performant, robust and that can scale to handle any load. Keep in mind the risks, think about resiliency, try to have contingency plans for events that can affect your business.
The road to building successful web applications is long and windy, and many things can happen over the life of an organisation. You have to make compromises, strategic decisions and there will likely be times when you have to take some risks, but with some thought and planning it’s possible to make that risk more manageable.
-
Web development technologies bucketlist for 2021
web development programming design
It’s the start of the year, so what better way to start the year than to make a list of technologies I’d like to learn and get experience with over the next 12 months:
Frontend
- Vue & React - I have done a bunch of tutorials for both of these frameworks and I’ve read the docs, and lots of blog articles, so I’ve got a good idea how they work, but I haven’t had a chance yet to build or work on a full sized production application using these
- Figma & Sketch - I’ve concentrated most of my web development on backend technologies, and most of the frontend work I have done has been using vanilla javascript and JQuery, with quite a lot of Bootstrap to get the UIs looking reasonable, so I’d really like to learn the basics of a design tool so as to be able to create wireframes and mock-ups, these two appear to be the most popular at the minute
- Web components - I’d like to build some UIs using the platform’s component framework, so that I can build robust UIs that will last many years without needing much refactoring and upgrades, I have a good idea how they work but haven’t had the time yet to build real world production apps that use them, so I don’t yet have a good sense of when they are the best choice for a frontend project
- Electron - In the context of web development it’s a frontend technology because it would be communicating with a NodeJS backend, but it doesn’t necessarily need to connect to a backend, it would be awesome to be able to create Desktop apps
Backend
- Elastic search - The text search I’ve done to date has been using the features offered by the MongoDB toolset which work alright, but for really great search, which is something most websites need, the best technology in town appears to be elastic search
- Kubernetes - Though I’m interested in serverless for some tasks/scenarios where it makes sense, I like to self host applications, usually on standard Linux VPS servers, however the new technology in town is clearly Kubernetes, which solves a lot of the infrastructure provisioning, and workload assignment challenges in a way that can be multi-cloud and well integrated with CI/CD systems
- Raspberry Pi - I’m super interested in the internet of things space, this could be just as a hobby initially, but I think these is the potential for a lot of interesting web development work in this space, I also have some long term pipe dreams of creating a hardware product at some stage in the future, Raspberry Pi seems like a great place to start
I might add some more if I think of any in the next few days/weeks. If I do I will post the update to the linkblog which you can follow using the RSS Feed.
Happy new year and I wish you all the best for 2021!
-
Building websites and workflows
web development programming workflows automation
I like to be up to date on the latest tech trends, and I read a lot of online tech publications. I post many of the interesting articles I find to my linkblog every day. Some of these trends start to become a bit buzzwordy, like artificial intelligence (AI), augmented reality (AR), blockchain and autonomous vehicles. All these technologies are everywhere these days, and they are great, but I realised today that I’m happy just building websites and workflows. When it comes down to it, that’s what I do.
The world of websites is massive, with different approaches necessary for both client-side and server-side code. What I love is that both in their own way require creative ways of solving problems. It’s incredible to me how much progress has been made in just the past decade on both sides of web development. New frameworks, libraries, cloud infrastructure, architectures, design patterns, tooling, governance models. It’s amazing.
And workflows have become so central to what and how we do things in a digital world that we hardly notice them anymore. It’s a very broad category, sometimes it’s just called automation, but the essence is the same, analysing how we are doing things, then streamlining and in some cases creating entirely new processes by stitching together a variety of off-the-shelf and custom software. Whether it’s file based media production, extract-transform-load (ETL) pipelines, continuous integration & continuous delivery (CI/CD) build systems, or infrastructure provisioning systems, there’s an enormous variety.
The boundary between the two disciplines is fuzzy, with quite a lot of cross-over, and new trends like the Jamstack and static site generators, because you can build websites using workflows! The boundary is an interesting place to be.
It’s totally possible that I might get involved in some of the buzzwordy trends in the future, but I’m happy creating efficiency, stability, robustness, and growth through technology by building websites and workflows.
-
Web design that focusses on text content is the best
web development design programming content writing
I love text focussed website. There are no annoying consent forms, paywalls or popups. The reading experience is the best. If there is an ad it’s usually relevant and unobtrusive. They load extremely fast, and are great for technical content.
The best ones:
- Load extremely fast, and are readable immediately
- Have a font that is well balanced and easy to read
- Have spacing between paragraphs, images and lists that looks nice
- Don’t re-render several times as javascript loads and fonts get swapped out
- Render really well on mobile devices without needing to zoom or pan the screen
- Render on mobile devices in such a way that the text takes up the entire screen with just a small margin at the edges
- Have the right font size that is easy to read
- Content layout that resizes correctly if you do need to zoom
- Have regular text that is visibly distinct from hyperlinked text
- Have tag or category pages making it easy to find other content
- Have easily findable links to information about the author
There are some big publications that have these types of websites but lots of smaller sites too. They aren’t always perfect, but that’s okay. It’s actually quite difficult to successfully create such a simple design. I do my best with my blog but I know the reading experience could be improved, perhaps with a different font.
Anyway I’m going to keep an updated list here of such sites that I really enjoyed reading:
- Drew DeVault’s blog
- Samizdat
- Web History by Jay Hoffmann
- Silicon Angle
- Openwarr
- BBC News - Science & Environment
Sexy design is great, but I find purely text sites refreshing these days.
-
The art of the minimal example
web development programming nodejs
I’ve been putting together a Portfolio of my work this past week. It’s been really interesting re-visiting the web development, workflow/automation and devops/sysadmin projects I’ve been involved with over the years. One thing that stood out was all the minimal examples I’ve built in order to either learn a technology or debug a feature.
Creating minimal examples is particularly enlightening, it’s actually quite a skill to be able to extract just the code you need to demonstrate a problem you are experiencing. It’s useful because you get rid of much of the complexity of the code you are working on and can focus in on discovering the root cause of an issue.
Stackoverfkow even has a special minimal reproducible example page which has guidelines on how to create one. For stackoverflow questions you would likely have just a few small snippets of code to demonstrate an issue
I’ve included a Minimals section in my portfolio, that links to many of the repos I’ve created over the years when I was looking to learn a particular feature or troubleshooting an issue I was experiencing. These aren’t strictly speaking minimal examples in the stackoverflow sense of the term, they tend to be a little bit more involved. In my case they are often small apps that implement just the feature I was exploring or debugging. They get rid of the complexity of the surrounding code, making it easier to reason about. I find myself often revisiting these minimals when I need to implement similar functionality somewhere else.
The ability to easily create runnable minimal examples I feel is one place NodeJS really shines, especially when you are building Express based web applications. This makes it easier to debug complex problems and communicate your findings to others you are working with.
Related post: Reasons to use NodeJS for developing your backend systems
-
Choosing your web development stack
web development programming nodejs
This is a bit of an aggregation piece, pulling together several thematically related posts that I think work quite well together to inform on the topic of choosing your web development stack. I’m a NodeJS developer so that’s my focus, but even if you are using a different language, a lot of the information might be useful in terms of building a broader understanding of the web development landscape.
Make it personal - When you are just starting out, a good place to start is to build your own website. It’s your chance to create your own place on the web. Nice recent css-tricks article that’s gets to the core of why building your own personal site is a worthwhile endeavour.
Deciding when to build a custom solution in web development - Sometimes referred to as the Build vs Buy dilemma, if you are developing websites, it’s important to be able to focus your efforts in the right place, this article gives you a mental model to help you decide when to build and when to use off-the-shelf products.
Reasons to use NodeJS for developing your backend systems - Self explanatory title, worth a read if you want to learn why people specifically use NodeJS.
Robust NodeJS Deployment Architecture - If you are leaning towards self-hosting, this article might be of interest, it’s more effort initially but you gain considerable portability.
I’m going to keep updating this post with other relevant articles I write or find online and I’ll post to the linkblog when the article gets updated, so you might want to add the linkblog RSS to your feed reader.
-
Deciding when to build a custom solution in web development
web development programming services
The web has been around for just over 3 decades now, with the capabilities of the sites we build increasing every year. With that forward movement there’s a corresponding rise in complexity. For website builders this presents somewhat of a dilemma. When you start out, you don’t have the experience to build things for yourself, but you still want to have an online presence. Luckily it’s easier than ever to get started quickly with many website builder tools available. But how do you know when building something custom is appropriate?
Answering that question when you are deep in the weeds of designing and building a site, can be challenging. I think it’s useful to have a mental model that enables you to step back and see the woods for the trees.
Building a website is a bit like building a shed. Right off the bat you can choose to buy a prefab shed, and that’s a perfectly good solution. The suppliers of these often have several models to choose from, so if one of them meets your needs, it’s going to be quick to get up and running. There is of course also the option to customise your prefab shed, make it look a bit more like your favourite style. However you might have some very specialist requirements, because of where the shed will be located, or maybe you need some electrical wiring for your home office which you plan to have in your new shed. In those situations it might make sense to build a complete custom shed that fits your requirements exactly.
It’s similar with software. There are many off-the-shelf solutions that might fit your needs. There are hosted services and also open source frameworks like Wordpress that will make it easy to get a site up and running, and enable tweaks using themes and plugins. In situations where this meets your needs, that’s probably going to be the best route.
Of course the web isn’t just sheds. The analogy scales up too. There are houses, hotels, community centres, sky scrapers, towns, cities and we can continue scaling up. As your infrastructure grows, your requirements will evolve. You’ll want to create resiliency, by splitting your backend into several components. To some extent you might be able to modify your Wordpress sites to fill these needs. But don’t assume that Wordpress will solve all your problems, it’s totally possible to build a custom Wordpress monstrosity, same goes for any custom software.
One of the downsides of the prefab solutions that large frameworks offer is complexity. Along with all the useful heavy lifting that the frameworks offer, comes a big increase in the amount of code. If you ever need to get into the code yourself, rather than have a developer modify it for you, it might be a challenge.
Having a custom solution that is very focussed on solving exactly the problem you are trying to solve, has the possibility to be much much more streamlined, less code, easier to understand if you ever need to get into it yourself. Starting small and growing progressively as your needs change can ensure that you don’t suddenly find yourself in a sea of complexity, overwhelming your efforts to get a site live.
If you are considering a custom solution, you might want to look at NodeJS. It’s designed specifically for network based applications, and it’s possible to build very focussed low code applications that are extremely performant and easy to maintain. I recently wrote about the reasons for using NodeJS for building your backend systems, you might find that interesting.
The analogy in this post was inspired by a recent Shop Talk episode. Great podcast that covers frontend and increasingly backend web development topics.
Hopefully this gives you a bit of a better idea of the software development landscape, and a neat macro way to think about your web development projects.
This post is part the choosing your web development stack series.
-
The coming revolution in freelance web development
web development programming freelance services
For most of the early web, freelance web development has been the norm. If you needed a website you hired a Wordpress developer and they hand crafted a beautiful website that met your needs. These developers had some backend development skills, but their real strength was frontend development, wrangling the html, css and javascript necessary to manifest your soon to be online property.
The web has evolved, and the websites people are building are in some cases becoming more complex, they aren’t only concerned with a nice place to present things digitally, but in addition with backend systems to handle various tasks, either through integrations with 3rd party cloud web services or fully fledged SaaS web applications.
Whereas previously these types of websites and applications were only built by large organisations’ in-house developers, the tooling, frameworks and technologies have progressed to the stage where it’s possible to embark on such projects with freelance developers. The world of freelance web development is broadening, and this is a great progression.
The wider industry still has to mature and reshape to accept this new reality. Developers doing this type of development have been siloed inside organisations, who’s hiring practices are anti-freelancer. This is something you realise pretty quickly as a freelancer when you apply for regular jobs. The recruitment process is structured in such a way that the freelancer has to pay for it. Organisations expect applicants to perform tests and take-home projects in addition to many rounds of interviews, and they don’t pay a penny. It’s a totally unsustainable backwards situation. Large organisations are expecting their recruitment process to be funded by individuals who are often struggling to get by. They are completely shocked when you suggest that they should be paying for your time. This keeps freelancers poor and in-house developers locked-in.
In my opinion freelancing should be the norm everywhere. Joining a company more permanently should be possible but the norm should be to start as a freelancer and then transition to a full time position. The work force should be more mobile, it should be easier for individuals to move between companies, or to operate independently, and to plant roots when it makes sense to do so.
The move towards remote work is accelerating this shift. Dan Andrews and Ian Schoen serial entrepreneurs and hosts of the TMBA podcast, in a recent Q&A episode (24:00) spoke about the myth that freelancers are more likely to leave, freelancer and business owner incentives and the improved innovation that freelancers can offer.
Dan is “Long freelancers”, he thinks the role that freelancers play is being redefined, and that in many ways the interests of business owners and freelancers are more aligned, with long term partnerships growing from initial low friction and flexible freelance engagements.
I’m on the freelance road, and it’s especially tough in these uncertain times, but I thought it might be useful to others to share my strategy as I move forward. I wrote about it on Indie Hackers. It’s very much like marketing and promoting a product, a multi pronged campaign to highlight my freelance services. I’ve also implemented a job interview policy that I am sticking to. It’s something that I have to do. It’s not sustainable otherwise. I encourage you to take a similar approach that makes sense for you.
I aspire one day to have an organisation that can fund it’s own recruitment process. One which works with freelancers as a normal way of doing business. I believe new ways of working have the possibility to improve the whole ecosystem. I think it’s an important topic that we should be discussing.
I would love to hear your thoughts about how you see freelancing will evolve over the next 10 years.
-
Reasons to use NodeJS for developing your backend systems
nodejs programming web development services
There are a lot of programming languages to choose from when it comes to writing server-side code. What makes NodeJS a good choice for this task? Whether you are embarking on a new project or extending an existing one, it’s a very relevant question. In this post I’m going to cover the main reasons for choosing NodeJS for your backend application.
Javascript the programming language runs in two main environments:
- The web browser which runs client-side javascript
- The server which runs server-side javascript
When programmers talk about server-side javascript they call it NodeJS, and when they write a NodeJS application they are actually writing javascript code. NodeJS is more than just the language though, it’s a whole environment (called a runtime) that, among other things, can execute javascript code, but it also provides a way for the code to access hardware like the storage and the network adapters.
The NodeJS runtime achieves this using an architecture that is optimised for creating network applications. This architecture is called the event loop.
The event loop looks very much like a collection of queues. As the code runs, anytime something has to happen asynchronously, i.e. that will take a while to complete, the code to be run on completion, called a callback, is placed in a queue, so that the remaining code to be run can continue executing without blocking.
Asynchronous tasks would be for example writing to storage or making an API call across the internet. The event loop architecture makes it possible for the NodeJS runtime to be single threaded, and we say it’s event driven because the data input/output (I/O) from the hardware doesn’t block the code. Instead of blocking, events are triggered once the result of the I/O operation is ready.
This means that NodeJS is particularly good for applications that operate over a network, because it can handle many simultaneous requests very easily.
That’s the big architectural advantage that NodeJS offers, but there are quite a few other reasons to build your backend using NodeJS.
Here is a summary:
- Runtime environment is particularly well suited and optimised to network applications, the event loop architecture makes it possible for single threaded code to execute in a non-blocking way, resulting in a high capacity for handling concurrent requests and realtime data
- The NodeJS foundation is particularly well organised with a very regular release cycle, including long term support (LTS) releases that have a published schedule
- There are working groups such as next10 and web-server-frameworks that collaborate publically, they have a clear strategic direction for the NodeJS project
- Npm hosts a vast collection of community built modules, with mostly open source licenses, greatly speeding up development
- Of all the interpreted languages it is one of the fastest. It uses the v8 javascript engine written in C++ by Google also used in the Chrome web browser, very regularly updated, always being improved
- There are a huge number of javascript developers worldwide since javascript also runs in the browser. This means finding developers is easier
- It’s possible to use javascript throughout the entire application stack, from the client-side code that runs in the browser, to the code running on the server, and also with NoSQL databases many of which use javascript as the query language. The elimination of context switching results in massive boost in developer productivity
- There is a vibrant tooling ecosystem with developers around the world continuously building and sharing the best development tools
- NodeJS is cross platform, running on Windows, Mac and Linux
- Using libraries like Electron and Cordova it’s possible to write desktop and mobile apps using NodeJS so you can have a single code base across mobile, desktop and web applications
- Typically promotes fast development, robust testing and code refactoring
- All serverless hosting providers have NodeJS implementations, microservices are very often written in NodeJS
It’s also worth reading the nodejs website about page for more details.
Companies such as Netflix, PayPal, Trellio, LinkedIn, Uber, eBay, Groupon, NASA, Mozilla, Twitter and Walmart are examples of big tech organisations that run significant amounts of their infrastructure on NodeJS. More details here and here.
NodeJS makes it possible to build extremely robust network applications quickly and at low cost, that are then easier and cheaper to refactor, extend and maintain.
This post is part the choosing your web development stack series.
-
How to become an official sponsor of the linkblog
linkblog javascript web development sponsorship
UPDATE (2020-12-20) - This blog post has been turned into a separate page, check out the sponsorships page for the latest.
It’s now possible to become an official sponsor of the linkblog!
I’ve spent time working for feature film visual effects companies and an enterprise software startup, and I’ve been running the linkblog for close to 10 years. It’s one of the longest running personal linkblogs on the internet.
The readership is very tech and developer focussed, lots of smart people working for big tech related companies.
What do you get as a sponsor?
- Your logo displayed on each linkblog day that you sponsor
- A special blog post at the end of the week thanking you and linking to your website (for 7 day sponsorships)
- A special mention in the newsletter that gets sent out on Saturday (for 7 day sponsorships)
The logo is right under all the links for the day, grouped with the patreon button.
It will appear on the main linkblog page which displays the most recent 50 days. It will also live on in the day and month archive pages.
Here’s an example of what it would look like for the month and day archive pages. It will look very similar on the main linkblog page
If you’d like to become a sponsor then get in touch with me via email.
-
What it’s like working for an enterprise software startup
web development programming automation workflows services travel
I wrote recently about my time working in the VFX industry during the height of the analogue to digital transition. I wanted to write another similar piece remembering my time working for an enterprise software startup in the file delivery space, so that I have something to refer to in future, but also because it might be useful to others to get a picture of what it’s like working in an enterprise software company startup.
First I worked as a Technical Consultant, and then as a Solutions Architect as part of the Global Operations team. I then joined the engineering team as a Software Developer, contributing to the development of a hybrid cloud file delivery SaaS. Having worked with many software vendors as a client in my time working for visual effects companies, it was eye opening being on the other side of the fence, with the folks building, marketing and selling vendor software.
When I joined they had a head office in Boston (US) and the engineering team in Ottawa, (Canada). Europe, Middle East & Africa (EMEA) was a new region for them, so there was no office. I worked from home in London (UK), or onsite at client locations, everything was done remotely. Initially we had to build the customer base, so there was a lot of travel throughout the EMEA region. There were times where I was travelling to several different countries every other week. I got a taste for being on the road and I liked it.
The company was pivoting from making source code replication software, to more generalised file movement software and they were focusing on the Media & Entertainment sector because the analogue to digital conversion was resulting in a need to move very large files. I was brought in to help grow the EMEA region and I worked closely with the regional Sales Director and Sales Engineer, meeting with clients, doing technical pre-sales, and later post-sales integration work, architecting and implementing a variety of media workflows.
I met with people from all levels, from engineers, developers, producers, journalists, managing directors, CEOs, CTOs to name a few. This was within visual effects companies but also broadcasters, channel aggregators, playout centres, network carriers, news organisations, radio stations, advertising agencies, system integrators, other software vendors, cloud providers, and occasionally clients in other sectors like oil and gas and automotive. Having exposure to a much wider section of the media landscape was incredibly interesting. I learnt first hand how these companies moved and transformed files, how they structured their organisations so that people could collaborate effectively, and the challenges they faced in moving to digital.
Another side that was super interesting was working closely with sales and marketing.
We had weekly sales calls at the end of the week, everyone in Global Ops would dial into the conference call no matter where we were. This was mostly the sales reps sharing how we were getting on with prospects, if they were on target to hit their number for the quarter, as well as any roadblocks they were up against. Occasionally the Technical Consultants / Solution Architects would be called upon. Us techies also had our own separate weekly conference call for more involved technical discussions. Although there was some competition between regions, we all collaborated together really effectively because we all wanted the entire company to do well.
At the time it blew my mind that we were all separately moving around while dialled into the sales call on our Blackberrys (and later iPhones). People transiting between clients in cabs, waiting for planes in airports, snacking in hotel lounges, zipping around on trains, or just in their home office, all across the globe, every continent. The first few years our phone bills were pretty insane.
The language in sales and marketing focussed companies is completely different to what I had experienced before. Everything revolves around the year being divided up into quarters, with Q1 starting in beginning of January and Q4 finishing end of December. It makes it easier to talk quickly about approximate timelines.
There are a lot of 3 letter acronyms, POCs (proof of concept), SOWs (statement of work), NDAs (non-disclosure agreements), RFPs (Request for proposal), QBRs (quarterly business review), ROI (return on investment), and many more. They make communication more efficient. The other thing there was a lot of was conferences, attending IBC in Amsterdam and BVE in London every year, hosting a booth where we did demos and presentations throughout the day.
As can be expected, there was a big focus on numbers, on your team hitting it’s quarterly quotas, with extensive use of Salesforce to track and forecast the sales process. It was noticeable to me the motivating effect of having a commission component to my compensation package.
I was often really impressed with how very complex customer relationships were navigated, with creative ways to move the sales process along, and the formation of strategic partnerships with people and companies with whom we had synergies. It was enlightening to see how much effort was put into pricing, and into relaying customer feedback to the product and engineering teams, and then to later see changes in the product that had been added in response.
As the EMEA region customer base grew, there was a lot more post-sales integration work. This is where I would work closely with the customer to architect the deployment of the software they had purchased. There was a lot of variety but generally they wanted a robust, secure and highly available infrastructure, and they often wanted to integrate our file movement software with their existing internal systems.
I wrote custom components in Perl that connected our software to existing systems using APIs or hot folder + XML file integrations. I then used these and pre-existing components in the product’s workflow engine to build multi step workflows to automate the processing of inbound and outbound files, sending them to 3rd party tools or to operators and digital artists for manual steps. Sometimes replacing old manual workflows, other times creating entirely new workflows that had never existed or been possible before. I would then install the software and custom workflows, test everything was working, get the customer to sign-off on the deployment and train the users on how to use the system.
These were some of the workflows I designed and/or built:
- ProsiebenSat – Ingest via Mx/Agent/Smartjog/Ftp, automated validation then manual validation, checking into MAM, export via Mx/Agent/Smartjog/Ftp
- Canal Plus - Ingest via FTP Pull/MX, media check, Agility transcoding, import into Sonaps and Avid editors
- Chellomedia - Ingest via Agent, movement of file bundles, Antivirus check, splitting of bundle on arrive in Lan, delivery of each piece to the right place
- TPC – Swiss Television - Avid export, transcoding, Sound recording, manual steps offered via Mx GUI, delivery to Playout
- Media City UK - Avid Gateway - easy ingest and outgest of avid projects
- Discovery UK - VOD preparation with automatic adding of bumpers, logos and subtitles, and automated quality assurance check
It was at times very chaotic. I remember completing a pre-sales demo workflow that used AWS SQS to receive files in the back of the taxi on the way to the client demo. I got it working on my laptop over 3G just as we pulled into the carpark. The live demo worked without a hitch. The total number of hours worked per week was very high, it was difficult to separate work and personal life, and the constant travel, though fun, did start to take it’s toll on me after several years.
Overtime we introduced processes, training programs, new staff, we started using a concierge to organise our travel and hotel bookings, we built cloud infrastructure to host many concurrent client POCs on VMs. Things got very streamlined and we were bringing in about a 1/3 of the company revenue.
I then moved over to Ottawa and joined the engineering team as a Software Developer, working on the team that was building a new SaaS file movement product. It was a nice change of pace to have an office again, and to be on a team of developers.
We followed an agile software development methodology, working on features in 2 week sprints, with daily standups, spikes, retrospectives and sprint planning. I worked closely with QA engineers and devops to ensure the features were thoroughly tested and deployed without issues, and with the support team to identify and fix bugs. The team was very well organised, and we shipped a lot of features. The product was adopted rapidly with the user base growing to 400000 users, made up of both existing and new clients. During that period I learned a lot about web development, it was a fantastic experience.
Aside from the occasional merge conflict, things ran pretty smoothly, there weren’t that many emergencies. We had weekly meetings where all the teams across engineering shared what they were working on. It was fascinating to be a part of the development process of enterprise grade software. It was a great foundation in developing web based software as part of an agile team.
I also experienced what it’s like to live in a very cold climate, with winter temperatures often down to -20 Celsius, having to use special snow tires, and learn how to drive in snow storms and ice rain. We had a team outing to go ice skating on a nearby lake, that was a lot of fun. I went over the provincial border to Quebec, met and spoke with french Canadians. They have a very different accent to people from France. I got to go snowboarding quite a bit and can now board pretty well in either direction.
-
Announcing my new Custom Training Service
nodejs web development automation services
I’m adding a new package to my professional services called the Custom Training Service.
Here’s the description from the services description page:
The custom training service covers the creation and delivery of custom training on web development and automation/workflow design and implementation. These can be made to according to customer needs and delivered either onsite or remotely via video conferencing tools. Other training topics might be possible.
I have previous experience developing custom training programs for
- Onboarding artists at vfx companies
- Rapidly documenting feature film custom workflows using video interviews
- Training users on enterprise software products
- Training users on workflow and automation integrations
My specialities are NodeJS web development and automation/workflows, but I could also create custom training programs on other topics.
In my previous work in this area, some of the projects involved onsite visits and consulting where I analysed the existing systems and processes prior to constructing the training program. I then worked worked with designers to create training material that was specifically tailored in look and content to the client needs.
If you have a need for some custom training, then don’t hesitate to contact me via email.
-
Looking back at linkblog.io
linkblog architecture infrastructure cloud web development portfolio automation
I recently announced the end of linkblog.io. I go into a bit of detail in this short indie hackers discussion thread. I wanted to do a quick retrospective to have something to refer to in future.
I’ve been running a linkblog for close to 10 years. In a lot of ways all the links I’ve posted chronicle my web development journey, but also just life in general. I found it a very useful tool and still do to this day. Somewhere along the way I decided to build a linkblogging SaaS product.
These were the high level goals of the system that emerged over time:
- Robust implemenation that does what it was designed to do and does it well
- Have a minimalist user interface, emphasis on text content
- Easily scalable to handle growth
- Deployable to standard VPS hosting
- Fault tolerant and able to have zero downtime deploys
- Resilient so that any server could be easily rebuilt from scratch using backups where necessary
From a technical standpoint I achieved all of these goals.
I wrote about Robust NodeJS Architectures earlier in the month, and this describes very closely what the linkblog.io infrastructure looked like.
Some other application level features and capabilities that are worth mentioning:
- MongoDB sessions support
- Redis sessions support
- Rate limiting using Redis
- JWT API authentication
- API Caching using Redis
- Backend job scheduling using Agenda
- Backend message queues using MongoDB
- Custom domains
- SCA compliant billing system (Stripe + webhooks)
- Production and staging environments
Implemented using bash scripts:
- Repeatable server provisioning system
- Application build and deploy system
- Backup and restore of certificates and databases
- Log file backup and cleanup
- Certificate renewal
Most of these features were added as a necessity in response to real world events that happened during development.
Though the UI is quite minimalist and mostly text based, there was quite a lot going on underneath. The system could have been quite easily and safely extended.
Finally here are some screenshots of the UI:
Landing Page - Header

Landing Page - Description
Landing Page - Features
Landing Page Latest News
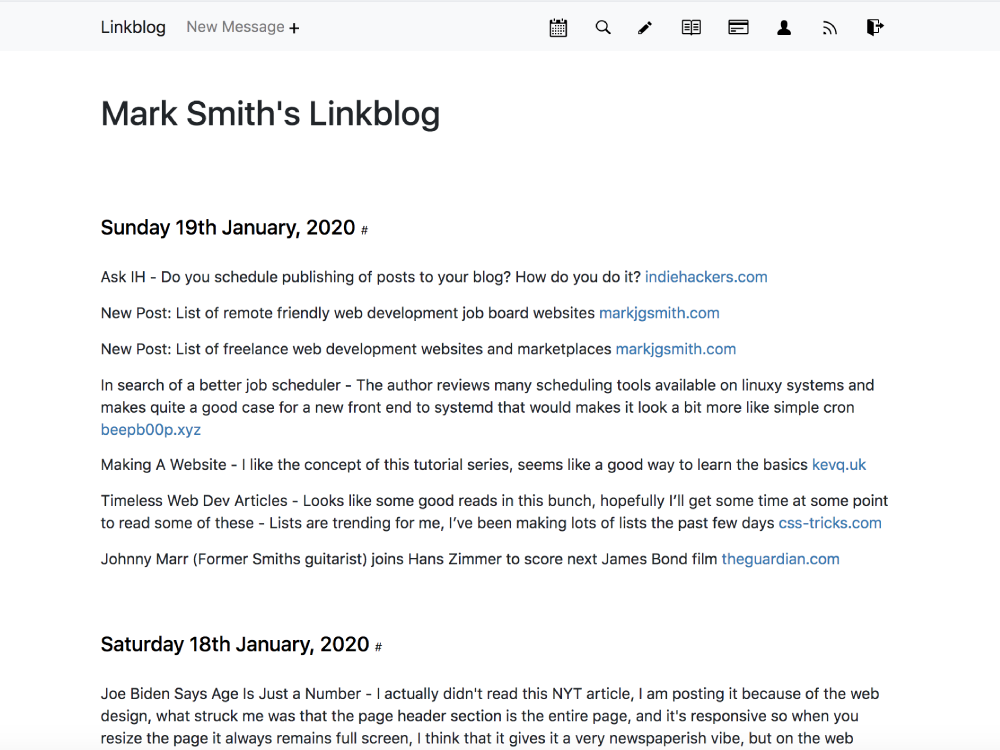
User Linkblog Page
User Post Message Page
User Archives Page
User Search Page
User Edit Mode Page
FAQ Page
User Billing Page - Fresh Load
User Billing Page - Add or Update Card Extended
User Profile Page
User RSS Feed
That was linkblog.io!
-
Linkblog.io is dead, long live linkblogging
linkblog programming web development newsletter jamstack
Linkblog.io the minimalist link curation tool, the Saas I spent 3 years building, is no longer live. All active users have been contacted and I’ve decommissioned the site.
Though the site was a tremendous success in terms of meeting my personal learning and development goals, building a robust SaaS from soup to nuts, ultimately I didn’t get the traction as far as user base that I had hoped for. Continuing to maintain the site didn’t make sense because it wasn’t generating any income.
I’ve been experimenting with Jamstack, Serverless and GitHub Actions and have built a prototype linkblog static site generator that I’m using every day. It builds 10 years of content in just a few seconds. It’s totally serverless. It’s pretty sweet.
I’ve been blown away with the possibilities that the jamstack opens up for creating custom content workflows.
I’ve also started a weekly newsletter where I share the best posts from the linkblog.
The general theme is javascript / tech / web development, but I also blend in some other topics from time to time.
I hope you like it, consider subscribing, it’s completely free!
All the best.
-
What it’s like working in tech in the visual effects industry
vfx programming automation workflows
I’ve built and supported many workflows for visual effects productions on big blockbuster movies.
Movies such as
- Mirrormask
- Are we there yet?
- Charlie and the Chocolate Factory
- Children of Men
- Harry Potter and the Goblet of Fire
- The Golden Compass
And hundreds more like those, working alongside digital artists and producers to build novel ways of collaborating. It’s been a few years now, I’ve since moved into enterprise software and now web development, but I thought it would be interesting to write a piece about my experiences in the visual effects (vfx) industry.
The landscape of the vfx industry is made up of a wide variety of companies, big and small, that work together to perform the post production on motion pictures. Ultimately they have the same goal - get the film finished on time for a theatrical release. There are often big budgets involved, and lots and lots of people doing a huge variety of jobs.
If you’re curious about how things are structured watch the credits of any film right until the very end. You can figure out a lot just from how the names are grouped together. Usually it’s the actors first then production staff, then all the post-production staff. But there’s a lot of nuance, with people being divided up into units based around certain pieces of the movie, say if it was filmed in different main locations.
It’s often surprising how many different visual effects companies are listed, each with their own teams of artists, engineers and producers. Of course animation based movies like the stuff that Pixar makes are nearly all post-production people, also huge amounts of post staff for all the superhero movies, but often films that don’t appear to have many visual effects shots, actually have loads of them.
The film credits of a movie is an art form in itself, with companies specialising in creating both the front and end rollers. If you stay right until the end of the credits in a movie theatre, a lot of the people remaining at the end, work in post. They want to see how things are structured at other companies, but they also just want to see their names or the names of their friends appear on the big screen. It’s quite a big thrill to see your name rise up across the screen when you’ve spent many months working on something.
I’ve worked in two different areas of the overall post-production movie pipeline.
First was as part of the engineering team in a reasonably classic vfx house, where we would work on a handful of movies in parallel, typically working on lots of individual shots, adding effects, then delivering these to companies upstream, who assemble all the vfx shots with the regular shots to create the full length movie. The work tended to happen right after production, or in some cases, at the same time as the movie is being filmed. There were often long days, and weekends, with some people working night shifts. These projects felt big, taking many months, with great wrap parties on completion. They also had a whole department that built old school physical visual effects, robotic monsters and weird creatures. Very cool but a bit scary when you are on the night shift.
There was a rather big render farm to render the effects onto the images. Hundreds of pizza box style nodes in racks, all managed by Pixar’s Renderman software. Organising the farm in an optimum way was complicated by the fact that 2D and 3D artists had very different types of jobs running. The 2D jobs were generally rather quick taking minutes, whereas some 3D jobs could take hours. You never wanted the 3D jobs clogging up the farm, but you also didn’t want the farm to be empty, and of course everyone’s job is very important. After a long time analysing the software and use cases we came up with a pretty effective configuration for the system.
There was a heavy focus towards Linux based systems, because it was easier to create multi-machine complex workflows using scripts written mostly in shell (bash/csh/tcsh) and Python. We would setup artists machines using shell environments in a neat way that enabled them to quickly switch between projects, with shot information pulled from a database, so they didn’t have to think about where the data was being stored, that was all automatic as long as they knew which shot they were working on, and everything was versioned. There were lots of cli system tools that for example did things with long sequences of image files.
For quite lot of the time I was there we had free toast, jams, Nutella, tea and coffee. That was nice. There was also a table football table and we held a yearly World Cup style competition, engineers vs 2D artists vs 3D artist. Good times.
The second vfx shop I worked for was further downstream, I was also part of the engineering team, receiving the finished shots from all the classic vfx houses. The work happened right at the start of post-production with film scanning and then right at the very end, after all the vfx shots had been completed by the classic vfx shops. We received all the shots and did various tasks such as colour correction, colour grading, beginning and end rollers, language versioning, subtitling, recording back to film, and creation of digital cinema distribution masters. The film scanning / recording and colour management tasks are often referred to as digital intermediate (DI), with the correction and grading being done by artists working with the directors and producers in specially constructed completely blacked out theatres.
We often had to meet impossible deadlines compounded by the fact that we were right at the end of the post-production process, impacted by any delays that happened at the other vfx houses. Missing our deadlines was just not an option, the penalties for which were in the order of millions of dollars per day, since the release date of the film would have to be moved.
This happened quite a lot:
Boss: How long will X take to do?
Engineers: 3 months
Boss: Ok we need you to do it in 3 weeks
Amazingly we always figured out a way to meet the impossible deadlines.
In this second place there was a much bigger volume of films passing through and typically the work on each film was on the order of weeks, the parties were mostly just for the producers interacting directly with the clients.
I mention the parties because I think it helps to illustrate that the overall vibe at different vfx shops can be very different depending on the type of work that is done. One isn’t necessarily better or worse, it’s just different. In broadcast media, where I’ve also had some experience, it’s yet another kind of different, more corporate in a way.
As far as tech goes there was a lot of cool hardware. Super specialist colour management boxes with unbelievably fast infiniband network connected storage, amazing 2D & 3D projectors, top of the line audio setups. The DI part of the facility could be hired out directly to clients, but our in-house artists also used it for the jobs we were working on.
Finished feature films took up terabytes (12TB for a full length 4k resolution film) of storage space, and the artists often worked on multiple versions of shots. Lots and lots of storage. Anytime new storage was added it got gobbled up pretty quickly. Problems with the storage had a big impact and cost a lot of money because no one could work. Stressful at times but generally there was a good camaraderie between everyone.
When I was there much of the movement of finished shots was done via USB drives, we had hundreds of them moving around town at any one time. I bet they still use drives quite a bit. Very manual but effective. You do what’s necessary to get the job done. I’ve been in situations where we had to send someone transatlantic on a plane just to hand carry some drives.
These days a lot of the finished shots are moved between companies digitally. There are high bandwidth networks between a lot of the post facilities. At the time, we were already experimenting with some very involved transatlantic workflows on some big films.where the director was in LA and the colourist was where we were in London. Making sure that the colour science equipment in both grading theatres was setup correctly was crucial. It was also quite fun because we got to work with the US team that was flown in for the duration of the project.
The film scanners which were about the size of two fridges side by side, were able to scan reels of film at around 8 frames per second, and they had a suite of Perl scripts used for automating the post processing of the all images created, so you could trigger custom scripts to process the scanned images on the render farm or other specialised hardware. Some of the reels of film would come in quite badly scratched, so we setup workflows to automatically digitally remove the scratches using specialised software. The only other way was to do it by hand frame by frame. The render farm there was smaller and ran on very fast blade servers. It was managed by a piece of software called Rush which is written in Perl.
There was always lots of things happening in parallel, so it was a little tricky not to step on each other’s toes. We were all trying to do this complex thing of creating digital effects all at the same time as constantly rebuilding and upgrading everything around us. If you went away on holiday it was quite usual for your desk to have moved by the time you got back. There were lots of emergencies, the business people were always trying to land new contracts with important clients visiting to see the latest version of their project, a sort of organised chaos. But we sure did make a lot of films.
The other thing that was happening at the time I was there, on top of the general day to day internal tech chaos, was that the whole wider industry was freaking out about the introduction of digital cinema. Every part of the ecosystem was being written and re-written all at the same time.
Was it cool? Yeah it was pretty cool.
I gained a solid foundation in using cool technologies, building infrastructure and workflows, figuring out new ways of collaborating, streamlining existing processes using both off-the-shelf / open source tools, and writing our own when necessary.
-
Why are people chopping off their legs with consent forms?
web development programming
A recent HN thread was discussing Why Japanese web design is so different. It’s based around an article written in 2013 but both the article and the thread discussion are an interesting read.
I believe that consent forms pose one of the worst usability problems the internet has ever seen, with big companies that have alternative news reading experiences benefitting immensely from the situation. Their products are slick and unbelievably lovely to use in comparison, but fundamentally non-weblike, featuring only big media brands and with no ability to link to articles.
I wondered if the US users knew how bad it had become, I asked about the prevalence of consent forms in Japan closing with:
Probably US users don’t know how bad it is because the US sites only add them to requests originating in the EU.
A canadian user commented that he didn’t think it was only EU users that saw the consent forms because he is seeing a lot of them too.
I don’t think that’s the case, if only anecdotally, as I have seen a huge uptick in these consent modals in Canada.
Most of these sites needed or wanted them implemented on the cheap. Restricting it to EU customers would require extra work…
If this truely is happening, it makes no sense whatsoever.
Why would a website owner that makes money from people viewing their website risk that by blocking users from viewing their website even when they are not legally required to do so?
Are they living in a strange parallel universe where money doesn’t affect them? (serious question btw)
There’s must be some crucial bit of missing information here, because it really makes no sense.
-
I've started a Newsletter!
web development programming javascript newsletter
Earlier in the week I met-up with James Clark from Nomadic Notes for coffee. He’s a long time travel blogger and digital nomad known for his excellent city travel guides. Really interesting guy with lots of insight into the travel blogging scene. It was great to meet him.
Yesterday his newsletter hit my inbox and I noticed that it’s powered by Substack. They’ve recently become very popular for their easy to use newsletter web application. I had coincidentally sent them a job application last week, turns out they use NodeJS. Anyhow I’ve been thinking about starting a newsletter for a while now, and this felt like a good time to do it!
So after deliberating a bit about which day to send it out, I settled on Saturday midday. Post-lunch BBQ time in Australia, tastey lunch time soup time in Asia, croissant and sausage sandwich time in Europe, in the Americas the midnight feast folks are going to love it, and for the others they’ll have something waiting for them to go with their breakfast burritos, cheerios and pancakes when they wake up.
It’s also a good way for me to delineate the start of my weekend. Something I’ve been missing for a while.
The newsletter is a roundup of the best links I’ve posted to my linkblog over the week. The general flavour is javascript / tech / web development but I also mix in other bits and pieces to get a good balance.
Subscribe for free in just a few clicks, the first issue is going out later today.
-
My policy on job interviews
web development programming services
UPDATE (2020-12-20) - This blog post has been turned into a separate page, check out the job interviews policy page for the latest policy.
I wanted to describe my policy on job interviews so that I have something to refer to in the future.
Over the years I’ve interacted with many prospects discovered online and done quite a few of these and I have had a number of bad experiences, which ultimately end up wasting my time and money.
I’m just one person and I cannot support people for all the myriad of exotic reasons they want to spend their time doing interviews. It’s exhausting and never ending.
For new accounts I have 1 short call to meet and get a high level overview of the project.
My policy then is quite simple. My hands don’t touch the keyboard until I am getting paid. Also if you want consulting services, it’s possible, but again you need to pay me for that.
For clients that want extended discussions, I suggest the consultancy service package which is delivered via video chat. We can verbally discuss code in any way you would like.
You can send me short code samples to read in advance if you’d like so we have something concrete to discuss.
What I suggest to clients that want to work with me live is to start with a 1-3 day development service package where you can have the time to work directly with me in a live setting.
I am open to long term arrangements and would be happy to transition to a more permanent role, but I could also continue on as a freelancer, whichever suits your needs best.
Check out the service package descriptions and price list for more details.
-
Mozilla MDN Docs are going full Jamstack
jamstack web development content programming architecture
Earlier in the year MDN Web Docs turned 15 years old. They have been around since the early days of the web and made huge contributions to it’s evolution. More info on their Wikipedia page.
But how big are they?
Let’s look at a few stats:
- 15 million views per month
- 3,000 new articles in the last 3 years, 260,000 article edits
- Grown in double-digit percentages, year over year, every year since 2015
- Serving more than 15 million web developers on a monthly basis
They are big!
They’re also doing a phenomenal job of organising the web’s developer documentation, adding new site features to make learning easier, while building a vibrant community.
So it’s big news when they decide to re-architect their platform, especially when it happens just after they announced 250 layoffs (1/4 of it’s workforce).
I posted on my linkblog a few weeks ago:
MDN Web Docs evolves! - the folks at Mozilla are going Jamstack + GitHub for their new MDN docs content contribution workflows, great writeup of the planned architecture, this is definitely an interesting space to keep an eye on, it will be really cool to see the collaboration workflows they build
Here is a link to the original article on hacks.mozilla.org.
Their writeup does a really good job of explaining the architecture changes they are making.
Essentially it boils down to this:
We are updating the platform to move the content from a MySQL database to being hosted in a GitHub repository (codename: Project Yari)
And the key takeway:
We are replacing the current MDN Wiki platform with a JAMStack approach, which publishes the content managed in a GitHub repo
In the piece they list many reasons including:
- Making it much easier to add new features to the platform
- Better contribution workflow, moving from a Wiki model to a pull request (PR) model
- Better community building by adding discussions, feedback, review and approve steps
- Simplified frontend architecture improving accessibility
And they go on to describe the planned architecture in a lot of detail with some illustrative diagrams. Jamstack website architectures are officially where new custom content workflows are being built.
I think this is perhaps a sign that there are some big shifts happening in web development, where the architectures that have powered the web for the past 10 years are being rewritten, enabling new ways of collaborating together to make digital things.
Which other large websites will make similar moves?
-
Robust NodeJS Deployment Architecture
nodejs architecture infrastructure cloud
The aim of this post is to succinctly describe an effective and robust architecture for self hosting your NodeJS web applications. I’m going to stay relatively high level, describing the technologies, and components, by the end of it you will have a good idea of what such a system looks like. There is a focus on standard well tested pieces rather than the latest shiny cloud / containerisation offerings. It is well suited for running small to medium size applications.

Features of the architecture
- Runs on standard VPS hosts
- Possibility to scale
- Secure
- Easy to maintain
- Fault tolerant
- Low cost
- Backed up and easy to restore
- Easy machine provisioning
- Easy to deploy code
- Support multiple databases
3 main components
- Load balancer
- Web and API application servers
- Datastore
During it’s life cycle, a client web request travels over the internet and eventually arrives at the load balancer where any SSL/TLS connections are terminated, then re-encrypted using self-signed certs and sent to an available application server. That application server performs the tasks it needs to do, persisting information on a shared datastore. Responses are sent directly from the application servers to the client.
The SSL/TLS termination happens on the load balancer because it makes managing the certificates much easier, with only a single place to renew, create, update and backup certificates.
Having a load balancer ensures that you can have several application servers running in parallel, which means you can scale by just adding more application servers, but it also means you can reboot servers without impacting site uptime.
As for the application servers, you can separate out web servers from API servers, but for ease of maintenance you can also just run both on the same machine on different ports, with a reverse proxy on the machine directing the requests to the right application. In this way you have one discrete unit which makes it much easier to add capacity. In the vaste majority of cases this setup is good enough, though could be optimised later.
Having a shared datastore is key to being able to run the application servers in parallel. This is a single machine that has a large storage volume mounted. It runs all the databases which write their data to the storage volume. The datastore can also run on a clustered set of machines for high availability, though this adds quite a lot of complexity, so initially it’s probably best to run one machine with good backups, so if anything goes wrong you can be restored and running with a minimum of downtime.
Technologies
- Nginx - Load balancer and reverse proxy
- Redis - Key/value very fast database often used for storing sessions and caching
- Mongodb - NoSQL database
- Postgres - SQL database
- Letsencrypt certbot - for generating and maintaining certificates
- Linux Ubuntu - Operating system for all 3 components
- Pm2 - NodeJS process manager, runs the applications, handles logging and a variety of other runtime activities
- RabbitMQ - Message queue software very important for fault tolerant backend systems
- Mongodb-queue - Message queue implemented via a NodeJS library backed by MongoDB
Provisioning infrastructure
You can keep things quite simple in this regard, using a Bash script for each of the 3 main components. The script would need to do the following:
- Install latest OS updates
- Install necessary software
- Configure users and groups
- Write/update software configuration files
- Start and stop various services
These are some of the important Linux items you would need to know about:
- sshd - server for ssh connections
- stunnel - creates secure connections, used on datastore for applications without built in SSL - e.g. Redis
- ufw / iptables - firewalls
- PKI and creating self-signed certificates
- logrotate - manage rotating and backing up application log files
- cron - schedule the running of maintenance scripts like backups
- certbot - generate and renew certs
- rsync - securely synchronize files between machines
It’s likely that your VPS hosting provider has an API and / or command line tools, making it possible to create a provisioning script that creates a VPS server, rsyncs the bash install script to the machine and runs it. So with a minimum of fuss you can provision fresh servers by running a script, so it’s completely repeatable.
It’s worth noting that there are modern tools that use containerisation like Kubernetes, which are very powerful but can get quite complex.
Deploying code
This is another place where a simple bash script can be very effective.
It would need to do the following:
- Build your application to a deploy directory
- Backup currently running app
- Rsync the files to the application servers
- Restart the application server
There is a lot of variety in this area. Many modern workflows that use CI/CD systems use git to clone your entire application repository to the server, rather than rsyncing just the built files. Requirements vary a lot from project to project.
The bash script route is great for simplicity, but there are often more manual steps involved, especially if your application has complex configuration. In the early days of a project it’s often good enough.
Backups
Backups are super important. You need to have all the important files backed up and ideally scripts to restore the backups in the event that a component fails and needs to be restored.
Consider backing up:
- Each deployed application version, along with configuration
- Log files for databases, firewalls
- Certificates
- Contents of all databases
- Configurations for every 3rd party application you are using
It’s a good idea to use storage from big cloud providers, they are low cost and have good scripting tools.
Security
It’s important to configure your machines securely, set firewalls (local and cloud) appropriately. Always use TLS/SSL for inter machine communication. Follow the security advice from the various pieces of software you install, for example creating different users for specific purposes e.g. application access vs access for backups. Only give the minimum of access rights necessary to perform a given task.
Staging and production environments
Once the application is running in production, you will benefit a lot from having a staging environment. It’s a replica of the production environment where you can try out new code without being worried to break the live system. Never deploy directly to production, always test it out in staging first.
Wrapping up
The infrastructure side of running applications can get quite complex, but there are a lot of advantages to knowing how to construct these setups yourself:
- Keep costs at a minimum
- Be in full control of the infrastructure
- Be able to deploy anywhere
It’s also worth experimenting with integrating serverless technologies for aspects that are very high load, the low cost and high performance might be worth the portability trade-off, but be aware that a move might require rewriting parts of your application should you need to change providers.
This post is part the choosing your web development stack series.
-
Self-hosted web based tool to get tasks done efficiently
productivity agile nodejs programming
A short while ago I was wanting to have a self-hosted tool to manage sets of tasks in an efficient way, so that tasks actually get done. I wanted it to be simple enough not to require much maintenance, with minimal chances of something breaking because of software upgrades.
I built a simple statically generated web based tool that is based on the agile software development methodology, which uses a “backlog” of “stories” that you complete during time periods called “sprints” (usually 2 weeks long).
Another key idea is that writing things down is a great way to focus on the task at hand and a way to drive your way as you forge your path.
It uses the Eleventy static site generator to render all the pages.
Here is the Github repo and there is a demo site with a bit of example data.
How does it work?
From the repo docs:
Use blog posts to describe your work, what you did, what you are about to do, then create “stories” that you add to the “backlog”. Assign stories to “sprints”, these last 1 week. Flesh out the stories, implement them, and then move these to “done” when you complete them.
At the end of the week do a retrospective of what you did, and plan (i.e. create and assign stories to the next sprint) for the upcomming week.
Whenever you are a bit unsure of your path, read the above 2 paragraphs. You probably need to write a blog post.
Benefits:
- Self hosted - run it in the cloud or just locally on you machine
- Everything is a file, versioned using git
- Create items written in markdown
- Easily backup your repo using one of the many git hosting providers
- Never have a migration problem, it’s all just text files
- Works offline
This is aimed at personal use rather than for large projects. I think for big projects, especially where you are collaborating with others, it’s probably better to use more comprehensive tools.
-
GitHub Actions for custom content workflows
workflows automation content linkblog nodejs jamstack programming
I’ve spent the past few weeks making some updates to the build system of the latest incarnation of my long running linkblog, now a statically generated website. In doing so I had my first chance to try out GitHub Actions and what I discovered is an extremely versatile tool that makes it possible to create a very wide variety of software developer workflows, centering predominantly around coding activities.
I believe another area where Github Actions might be very effective is in modern collaborative workflows for content creators. And this is happening now because of the recent resurgence of building static websites in a way refered to as the Jamstack.
In this post I’m going to describe the pieces of the puzzle, and the types of workflows that are possible, but without a lot of the complicated jargon.
Github is most well known for hosting repositories, places where developers can collaborate on code. It’s really a web interface for the open source git command line tool, which can be used completely separately, but their interface has become very popular over the past few years, and they are a big reason why there has been a renaissance in open source software.
Github Actions is their workflow automation tool, and it has a focus on automating tasks in and around repositories. It makes it possible to trigger custom actions when various repository events happen, such as adding new content, or when users have reviewed content, or when discussions mention a certain keyword, and lots more. It’s really very versatile.
The Jamstack movement is a way to build websites that has become popular recently. It focusses on pre-rendering all the pages of a website so that they are static files, rather than have a server running an application that dynamically renders the pages when they are requested. There is a lot of variations and nuance to what it encompasses but that’s the general idea. A lot of the technology isn’t actually new but it’s the first time this way of thinking about and building sites has had a name, and it’s resulted in some very interesting forward motion in how websites are built.
There are a lot of benefits to Jamstack sites including:
- Security because there’s no server to hack
- Speed because all the pages are pre-rendered
- Being a naturally a good fit for automation
And it’s this last point that opens up new possibilites for collaborating.
I’ve been running my linkblog for close to 10 years, there is a lot of content, but it’s possible to render out all the site pages in just a few seconds. I’ve built my own static site generator (SSG) tool in NodeJS because I’ve been able to optimise for that use case specifically, but there are many open source SSG tools out there.
One of the major benefits of creating a content workflow that uses git, is that you gain all the safety that makes it a great code collaboration tool. By using similar, all be it simpler, workflows to developers you can be quite confident that you won’t loose any work. It’s all just text files, and everything is versioned. As well as safety you get a considerable amount of future proofing because in the end it’s all just text files, so much less danger of software update breakages, and since it’s based on standard git tools you can move to another hosting provider relatively easily. Most of the providers have their own workflow tools but there is some interoperability, Bitbucket for instance can run Github workflows, and making platform specific tweaks isn’t that difficult in a lot of cases.
As an example, for my linkblog I have some HTML forms built using serverless cloud functions, that I use to easily add new content to a Github repo throughout the day. I have a scheduled workflow that runs at the end of every day and merges in the new content in a safe way using what is called a ‘Pull Request’, often referred to as a PR. This makes it easy to revert the merge if that’s ever necessary. There is then another workflow that detects newly merged content and triggers a site re-build, and then a deploy to the website hosting provider, and the site is live with the new content.
It’s also possible to use some of the other tools that Github provides as part of the workflow, for example the Issues and Pull-Request pages, to create places where you can discuss new additions with collaborators, as well as setup notifications, and to only publish content that has been approved by a certain number of reviewers.
It’s not strictly text based content either, as part of my updates I added a podcast to my website. The files are hosted outside of Github, but the GitHub action renders all the podcast pages and creates the RSS feed.
If you want to listen to some very experimental audio, the show is in iTunes!
Also if this type of content workflow is interesting to you, feel free to get in touch with me to let me know. I might post more details, tips and tricks about the workflows I am using.
I’m also available for hire on projects you have. Check out my Github profile.
-
Test Post Written Using Github
github blogging
Just a quick test to see if it’s possible to write a blog post directly in Github.
Usually when you push to Github using git, it triggers Jekyll to rebuild the static site, but I don’t know if that happens if you save the file directly to the repo without a push. Based on this stack overflow post looks like it probably doesn’t but figured I would test it out just in case.
Update 1: It worked! My first attempt didn’t work because I forgot the .md file extension, once I got the file name right, the build was automatically triggered. Saving the file now should result in another build which will add this update.
Update 2: The update resulted in a site build too :)
Update 3: However I now see that though there is an edit button for files that already exist, there is no “create new file” button in the mobile version of guthub.com :(
-
List of remote friendly web development job board websites
remote
When looking for remote web development opportunities there are broadly two categories - freelancing and remote positions.
Here is a list of websites for finding remote position opportunities:
- Weworkremotely
- Workingnomads
- Remoteleads.io - Contract and part-time remote jobs
- Remote.io
- Angel.co
- Remoteworkhub
- Remote.co
- Remotive.io
- Skipthedrive
- Outsourcely
- Europeremotely
- Remotelyawesomejobs
- Landing.jobs
- Remoteok.io
- Stack Overflow Remote Developer Jobs
- Nodesk.co
- YCombinator - Look for monthly “Who’s hiring?” and “Who wants to be hired?” posts
List of remote friendly companies:
Also worth checking out is this list of resources for remote workers.
For freelancing check out my list of freelance web development websites and marketplaces.
-
List of freelance web development websites and marketplaces
freelance web development
When looking for remote web development opportunities there are broadly two categories - freelancing and remote positions.
Here is a list of websites for finding freelancing opportunities:
- YCombinator - Look for monthly “Freelancer? Seeking Freelancer?” posts
- Upwork
- Freelancer
- Toptal
- Gun
- Freeeup
- Codeable - Sepcialises in wordpress web development
- And.co gig List
- And.co freelance Jobs
- Gigster
- MoonlightWork - Has a Stripe integration
- Authentic Jobs
- Indeed
- Guru
- People Per Hour
- Craiglist
- Github
- Find Bacon
Also worth checking out is this article that has lots of details about freelance contracts.
For remote positions check out my list of remote friendly web development job board websites.
-
Setting up as a freelance web developer
freelance web development
There are lots of reasons for doing freelance work, whether it’s for what people refer to as a side hustle or whether it’s more of a full time freelancing goal, but in all cases it’s necessary to have a minimal infrastructure setup. You fine tune this over time and adjust according to the direction of the projects. Broadly speaking the essentials are payments, contracts and some form of marketing.
I got some of the details from this article from an audio on soundcloud called Web dev freelancing high level overview basic setup. The author makes some good points and is worth the listen.
Payments
Freelancers need a way to receive payments. There are a lot of online services that specialise in providing services for freelancers. Freshbooks seems to be a favorite for a lot of web developer freelancers. I hear it mentioned a lot on podcasts. Whichever service you choose, you will need to create an account, connect it to Paypal, and connect it to your checking account. It’s a good idea to setup a seperate checking account for your freelancing work than your personal banking account. Then it’s a good idea to test out the setup by sending a $1 invoice from Freshbooks, pay and ensure that the money reaches your paypal and then bank account.
Another possibility here is to use a partly self hosted solution. You will need some web development skills, but you could use the Freelancer project (One of my projects) to host a payment site that uses Stripe as the backend payment provider. You can host the code on a public Github repo, so customers can inspect the code if they want.
Joan from Toptal contacted me after reading this post to inform me that they have just released a freelance calculator tool that could be useful to easily figure out your hourly rate and yearly income. Thanks Joan!
Contracts
You will need some basic freelancer contracts that will clearly set out the project goals and responsibilities, and a way to send these contracts back and forth securly. Docusign has been recommended a lot, but there are other similar services available online, easily findable via Google search.
As far as the contract google search ‘standard exchange of services contract’ or ‘web development contract’ and use one of these as the basis for your contract. Make sure that the contract contains at least the following:
- State that you will build website, describe the website, pages, api etc
- State the price for building the website
- Client will pay 1/3 before, 1/3 midway, 1/3 at the end
- After contract finishes, will leave project
- Hourly rate applicable for maintenance after contract finishes, should be arranged as a seperate engagment
Also worth checking out is this article that has lots of details about freelance contracts.
Marketing
Some way to promote your services, this doesn’t need to be too envolved initially.
A basic website with a logo, contact details, short description of the services offered. Something you can add to the footer of your emails, it will be useful for referals too, a way for other to point people towards you. You might want to setup a blog at some stage, but initially a basic 1 page website should be enough.
How to deliver
General advice is to deliver a working website using new accounts for hosting and give these to customer as a deliverable. Hosting your customers website is not advised.
Now you have the basic infrastructure to make proposals, draft contracts, and receive payments.
Related posts:
-
New Linkblog feature: rss, atom and json feeds
linkblog protocols
The latest linkblog feature is feeds. These are a versions of your linkblog that are easily readable by a computer. This makes it easier for people to read your linkblog but also enables you to do neat things like auto post your links to social media such as Twitter and Facebook. Each time a day finishes where you posted links, the hash link of that day gets added to your feed.
To access your feed, right click on the icon in the toolbar (it looks a bit like the Wifi symbol rotated by 45 degrees) and select copy link address. This should copy the url of your feed to your computer’s clipboard.
If you then paste it into some form of text editor you will see what the feed url looks like. Here are my feeds for my regular linkblog and for my custom domain linkblog:
https://linkblog.io/users/mark/feeds/daily/rss https://links.markjgsmith.com/feeds/daily/rssThe advantge of using your custom domain url is that theorectically if you ever needed to move your linkblog to another provider, then as long as you still own the custom domain, that could be done without the people already using your feed having to update to a new url.
If you try to load these pages in a browser you’ll see lots of strange looking text with HTML tags, but you will also notice that your daily posts are within <item> elements. Computers can read these feeds easily. The vaste majority of the time though you never need to read the actual feed, you only really have to copy and paste the urls of the feed.
The most common type of feed is RSS so that’s what is used in your navbar. Atom and JSON versions of the feed are also available by replacing ‘rss’ in the url with ‘atom’ or ‘json’.
A very typical thing people do with feeds is add them to their feed reader, which makes it possible to read many sites from 1 place rather than have to remember to visit all the sites individually. Seen like this, feeds are very similar to the follow feature in many social media sites, they have the advantage of working across many different sites, though they are a bit more complicated.
Feeds also make it possible to do things automatically with your posts, like posting them to sites like Twitter or Facebook. For example I have setup my linkblog so days are posted to my Twitter account @markjgsmith. There are lots of 3rd party online sites that offer rss-to-[insert favorite social media site] type services.
For a more detailed description about feeds check out the You Need Feeds site. Also useful is this list of rss feeds for social media sites which might give you some ideas about what is possible.
If you want to try out running a linkblog then signup for the 14 day free trial, after the trial it’s just a few dollars per year.
-
New Linkblog feature: highlightable messages
linkblog
A big part of linkblog is the ability to see the context around a link, to see the other links that were posted on that day. It’s been possible to link directly to a day in your linkblog since the beginning. But until now, it hasn’t been possible to link directly to a specific message in a day.
For example here is the link to yesterday in my linkblog. These day urls are copyable from the hash link (#) next to each day.
The latest feature is the ability to link directly to a specific message in a day. When the page loads from a highlightable message url, the message that is specified in the url will momentarily be highlighted. After a few seconds the highlight will fade back to the regular linkblog page. This strikes a good balance between being able to point directly at a specific message while also keeping the context around the message focussed.
After loading a linkblog using a highlightable message url you will know which message was being referenced but also be able to see clearly the context of that message. Note that you have to have javascript enabled in your browser for the feature to work.
One challenge implementing this feature was how to do it while minimising the effects on the linkblog page. Adding a clickable element next to each message on the page to copy the url to the clipboard would negatively impact the minimalism and readability of the page. For the moment the way to get a highlightable message url is from the search page.
Each message in the search page results has a highlightable message url as the hash link. Since most often users will probably be searching for the most recent messages, I’ve updated the search page so that performing a search with an empty search box returns all the messages with latest listed first.
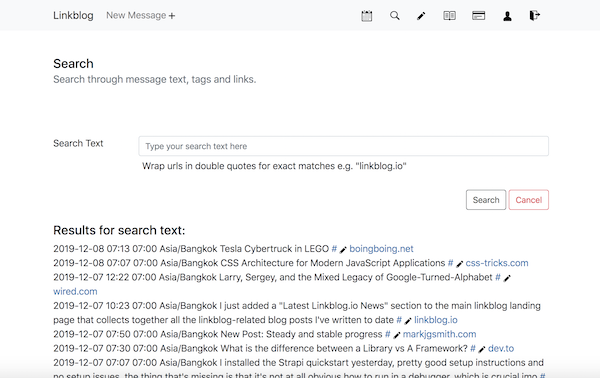
I hope you enjoy the new feature!
-
Steady and stable progress
linkblog programming
Along with the linkblog site redesign and more recent foundations building, I’ve made steady progress with other items too, including:
- Improved useability during signup, activation and onboarding
- Built foundation for upcoming SSL for Custom Domains feature
- Added tags to profile page data exports
- Optimizations for custom domains
- Database connection improvements
- Kept 3rd party modules up to date
- Faq and privacy pages updates
- Code build and deploy system overhaul
- Server provisioning system overhaul
- Refactored analytics for better anonymization
- Improved security with CSP policy
- Improved integration and unit tests
- Frontend optimizations by using compiled templates on client
- Better data validation
Because of previous work done to build a staging environment and load balance the site across several nodes I’ve been able to make all these changes while keeping downtimes to a minimum.
Here is the status page for the previous month:
-
Building the foundations for the future of linkblog
linkblog programming
Earlier in the year I did a pretty big redesign of the site which lead to upgrading the style framework which ended up being rather a lot of work, but the site looks great now and still minimalist. The redesign resulted in me building and introducing 3 new core components:
- Redesigned billing system - Compliance with EU Regulation
- Scheduler - Periodically runs jobs completely separate from handling website requests
- Queues - Mechanism to co-ordinate scheduled jobs in a fault tolerant way
This post gives a bit of description around these components, because although they are not directly visible in the linkblog UI, you might find it interesting to know some of the details of how the site operates under the hood, and maybe give you a bit of an idea of the possible directions for the future.
If you’ve been following the news you might have noticed that there has been a wave of introductions of new internet regulations all around the world. In the EU they have introduced Strong Customer Authentication (SCA) which affects linkblog because the servers on which the site runs are hosted in the UK. The new rules meant a complete redesign of the billing system and with only 60 days notice. The previous integration with the payment processor Stripe was using their Checkout product, which was simple to setup but doesn’t meet the new EU regulations. The re-architected integration is more complex and uses a combination of Stripe Elements for the UI and the new Stripe Intents API which complies with the latest EU regulations.
The billing system is now active and whereas previously it could only handle 1 type of subscription, it’s now ready to handle multiple subscription types, the first addition to the Linkblog Basic subscription is likely going to be SSL for Custom Domains, the plan is to slowly add new services to compliment the basic functionality.
As part of the billing system redesign, it became apparent that I needed a way to receive status updates from Stripe called webhooks. Handling the webhooks is non-trivial because an acknowledgment has to be returned immediately, the same webhooks sometimes get sent multiple times, the order isn’t always guarantied, the task necessary to process the webhook differs depending on the type of webhook received and processing tasks take varying lengths of time to complete.
The strategy I settled on was to record the incoming webhooks in the database, respond to Stripe, and have a scheduler component run jobs to periodically process the recorded webhooks. I had to restructure the app quite a bit to be able to handle regular website requests and also separately run scheduled jobs. This is a good strategy but problems occurred because when a cluster node was rebooted, there was the possibility of jobs failing midway through and not completing.
To make the setup fault tolerant I had to build a queuing system to help orchestrate the scheduled jobs. The queues are hosted on a separate machine to the website cluster nodes, and the scheduled jobs which periodically run on these read and write messages to the queues during execution. Queues are useful because if a website node goes down midway through a job, another node can automatically pick up the job and finish the processing when it sees the item in the queue didn’t complete within a certain timeout period.
So a webhook arrives, is recorded in the database, and scheduled jobs run and add messages to the appropriate processing queue. These queues are monitored by more specific scheduled jobs running on the nodes which take new items off the queues and carry out the appropriate processing tasks, for example sending out email notifications.
The cool thing about queues is that they can be used for lots of tasks that don’t need to be part of handling website requests. I’m hoping to migrate a bunch of tasks like data exports and generating custom domain certificates to use the queuing system in the near future. Being able to off-load tasks to the queues will keep the site performing well.
The new billing system, the scheduler and queues are 3 core components that are fundamental going forward.
-
Linkblog new look
linkblog design
Linkblog has had a site redesign!
The redesign was actually done and released several months ago, but there were quite a few changes needed after the redesign so this is the first chance I’ve had to blog about it.
Part of what I learnt from the launch on Indie Hackers was that people really wanted a way to try out the software before committing to a subscription. So as part of the redesign I also updated the signup process so that the initial signup creates a 14 day free trial (no credit card required).
The redesign itself is based on one of the free bootstrap themes from Themes For App, I customised one of the themes to create the main landing page, signup and signin pages.
The rest of the site needed a bit of a refurbish so I decided it was a good time to upgrade the style framework I use called Bootstrap from v3 to the latest v4. I was able to get rid of some rather crufty old frontend code and replace it with new bootstrap components that use solid and modern CSS. Visually the site is a lot cleaner, the most obvious change is the toolbar along the top of the page which has changed from solid black to a lighter grey, which I think along with the other improvements in the latest Bootstrap results in a site that is nice to use and keeps with the minimalist ethos.
One big issue was that the latest Bootstrap broke the site content security policy (CSP) which ensures that only the right 3rd party libraries get loaded into the pages. There was a related CSP issue on the repo and with the help of the commenters I found a workaround to make sure that the site is still secure. According to the bootstrap devs, the CSP issues will be addressed in v5.
Little did I know that the redesign was only the beginning of a long voyage of discovery, though there wasn’t a whole lot of actual movement so it’s more a voyage of the mind and keyboard. I’ll be following up this post with a summary of the recent major changes in the linkblog foundations.
I hope you like the new look!
-
Linkblog featured on 10words
linkblog
Linkblog is featured today on 10words.io, currently on the homepage and will also go out via their newsletter and twitter!
To all the 10words readers - thanks for stoping by!
A good example of a linkblog is my linkblog which I also publish using the custom domain feature so that it nicely fits in with my other web presences.
Some other examples of use are posting links to blog posts and finding a video you watched last year and the latest feature addition is the navbar globe icon. Running a linkblog is a great way to build some context around what you are doing.
This blog post wouldn’t be complete without a coupon code. If you’ve read this far then you’re at least curious, if you use coupon code 10WORDS at check out get 30% discount on your first year, and it’s a 30 day money back guaranty.
-
New Linkblog feature: navbar globe icon
linkblog
The navbar globe icon feature adds a way to link to your other online sites. To set it up, simply update the url form field on your user profile page. Then a globe icon will render in your public linkblog’s navbar that loads that url when clicked.
It’s a minimalist way to link to your other sites from your linkblog, so visitors can find your other presences online. In the screenshot below notice the globe icon in the top right just next to the search icon, and in my case it links to my homepage, which has links to all my other online sites, so visitors have a way to find among others my blog, twitter, linkedin.
See it in action here.
-
The dead simple todos system
productivity programming bash linux
Over the years I’ve tried a variety of sofware solutions to todo lists but I always find that eventually I end up just opening a empty file and typing a text list. It’s just so straight forward. Almost as if writing a list in a notebook, which of course is the ultimate todo list solution.
Anyhow I’ve been adding quite a lot of aliases to my dotfiles recently and I wondered if I could add just a few that would make the bare essentials of a todo list system. These are the aliases that I came up with:
alias 'slugd=date +%Y-%m-%d' alias 'todos=cd $TODOS_DIR' alias 'tdf=echo $TODOS_DIR/$(ls $TODOS_DIR | tail -n 1)' alias 'tdt=echo $TODOS_DIR/$(slugd).txt' alias 'tde=e $(tdf)' alias 'tdd=echo "### $(date "+%A %d %B, %Y") ###"' alias 'tda=cat $(tdf); echo' alias 'tdc=cat $(tdf) | grep "[x]"' alias 'tdi=cat $(tdf) | grep "\[ ]"' alias 'tdn=TODOS=$(tdi); ! test -f $(tdt) && tdd > $TODOS_DIR/$(slugd).txt && echo >> $(tdf) && echo "$TODOS" >> $(tdf) && tda'It’s all very standard shell scripting, the aliases get loaded from
.bash_aliasesor similar. The only complicated one istdnwhich only creates the new todos file if one doesn’t already exist for the current day to avoid accidentally overwritting an existing list.- slugd - create slug using date
- todos - fast navigation to $TODO_DIR
- tdf - (file) prints latest existing todo file path
- tdt - (today) prints file path using todays date
- tde - (edit) opens latest todo file in editor
- tdd - (date) prints todays date nicely formated
- tda - (all) prints all todos from latest todo file
- tdc - (complete) prints all completed todos from latest todo file
- tdi - (incomplete) prints all incomplete todos from latest todo file
- tdn - (new) new todo file extracting all incomplete from previous
In practive the only aliases you actually use are
tdn,tdaandtde. That’s it just 3 aliases to remember and it’s pretty close to using a notebook. The only configuration necessary is to setTODOS_DIRenvironment variable somewhere that gets loaded by the shell automically like your shell’s.bashrcfile.Here is what a todo list file looks like:
~ $ tda ### Saturday 07 July, 2018 ### [ ] Install new theme on blog [ ] Deploy live keys to payments pages [ ] Troubleshoot failed mail deliveries [ ] Add links to freelancer github repo on payment pages [x] Troubleshoot github remotes issue on markjgsmith.com [x] Troubleshoot freelancer left pane image centering issue [ ] Re-organise dotfiles and dotfiles local [x] Add todo aliases to dotfiles [ ] New blog post: The dead simple todos system ~ $The real test of course is tomorrow morning when I create a new todo list.
-
Commands I ran to install rbenv and upgrade ruby versions
ruby programming
I was able to upgrade ruby versions. These are the commands I had to run. I will spare you the error messages and detours.
~ $ ruby -v ruby 2.3.0p0 (2015-12-25 revision 53290) [x86_64-darwin14] # Commands to install rbenv and latest ruby brew doctor brew update brew install rbenv echo export PATH=$HOME/.rbenv/shims:$PATH >> $HOME/.bashrc brew upgrade ruby-build rbenv install --list rbenv install 2.5.1 echo 2.5.1 > ~/.rbenv/version rbenv rehash rbenv versions gem env gem install bundler ~ $ ruby -v ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-darwin15] # Re-install the gems in the blog installation directory bundle install bundle show jekyll bundle exec jekyll serveThese are essentially the commands I ran, roughly in that order but it got a bit confusing somewhere in the middle.
I decided not to run
rbenv init, the only mandatory thing it does is add the shims folder to the PATH. So I just did that myself. -
Ruby jargon to Nodejs jargon translation
nodejs ruby programming
I’ve been making quite a lot of modifications to the blog recently. The blog is generated by Jekyll a tool written in the ruby programming language. I have been seeing a lot of warning messages about ruby versions during builds, so it’s time to try to figure out what’s going on.
Everytime I’ve ventured into this area it’s been full of confusing articles and definitions that don’t seem to quite match up. I found an article comparing the rvm and rbenv ruby version managers, which along with my browsing various ruby sites and blogs and quite a lot of head scratching resulted in the followng translation which might be of use to other nodejs developers:
- ruby === node
- rubbies === versions of node
- RubyGems.org === npmjs.com
- gems === node modules (packages hosted on npmjs.com)
- gemsets === node_modules folders (there can be many)
- Gemfile === package.json
- gem === npm
- bundler === yarn
- rvm === nvm
- rbenv === simpler rvm
Something to be aware of is that rvm apparently also overides the system cd command to automatically set ruby on directory change which might not be desirable.
I don’t claim that the list of correct, it’s just what I’ve come up with so far. Email me with any corrections.
-
Description of my freelance NodeJS and automation software services
freelance nodejs web development automation workflows programming
Update - This is the blog post that constituted the original services description, it is no longer being updated and has been replaced by the services page.
The consultancy service is very straight forward, it covers any aspect of building cloud web applications and is delivered via Skype call. It is customizable to the clients needs but generally covers architecture, building and deployment as well as things like efficient setup of developer environments.
The infrastructure service deliverable is a running cloud based system ready for web application deployment. There are lot of tweaks necessary over and above the vanilla Ubuntu install that your cloud provider offers, such as machine access, cloud provider environment setup, firewall rules, logs, 3rd party applications installation and configuration, user accounts, aliases, SSL certificates, cron jobs to name a few. This services covers all these and does it at 3 complexity levels depending on the size of your installation.
The maintenance service is aimed at maintenance and support of a web application infrastructure. It should be used for upgrades, improvements and customizations to an existing infrastructure.
The development service covers the development of NodeJS based web applications and could cover any type of application. It also covers the development of software based automation and workflows. I recommend doing some consultancy services sessions first to determine the application specifics before starting a development services engagement.
The custom training service covers the creation and delivery of custom training on web development and automation/workflow design and implementation. These can be made according to customer needs, could involve a systems discovery and consulting phase, and delivered either onsite or remotely via video conferencing tools. Other training topics might be possible.
The writing service is aimed at internet publications that wish to create content for their websites. It could cover any aspects of web development, and might be in the form of a tutorial or perhaps an essay expressing an opinion on a particular aspect of modern technology. The details could be fleshed out via a short consultancy service.
The pricing page has the full list of the packages for each service. If you would like to purchase some software services or products visit the payments page.
-
How I use my linkblog - posting a link to my latest blog post
linkblog
Situation:
Earlier I wrote a how to blog post. It would be nice to add it to my linkblog timeline in case anyone stumbles across my linkblog. Then they might get a better idea of how a linkblog might be useful. It might also be interesting to others that are building software and writing documentation to see my flow.
Solution:
I open the post in my web browser, load the blog post I just wrote and click the bookmarklet in my browser bookmarks bar. I added the popup bookmarklet to my browser bookmarks bar when I setup my linkblog account.
The popup window appears and I add the text “New Post:” to the start of the message text. When I am linking to a blog post I wrote, I always add this prefix so that I can easily search for them later, and it also draws a bit of attention to the link for people that might read my linkblog.
I click on the ‘Meta’ tab and add some tags. While typing the tags, a drop down appears under the tag box to suggest tags that I have previously used in posts. I click the tag in the drop down and it autocompletes the tag in the tag boz or just continue typing and hit enter when I am done typing the tag. Tags can have spaces in them but no underscores.
I jump back to the main tab and click the “Post Message” button. The window disappears as if it was never there. I open my linkblog and find that a new item has been posted linking to the blog post.
-
How I use my linkblog - finding a git tutorial I watched last year
linkblog
Situation:
I need to commit some changes to my dotfiles, when I do a git diff I see that there are two distinct changes that have been made because I must have forgotten to check the previous change in, no doubt I was distracted by something much more impotant at the time. The world is like that sometimes. Other people are just so me me me sometimes. :)
I could check these commits in one commit, it’s no big deal, they are my dotfiles in any case, it won’t matter really. On the other hand I know there is a git command just for this called patch, but I don’t use it very often and I don’t remember the flow. However I do remember that I watched a tutorial on youtube but it was a long time ago, at least a year. I did post a link to it on my linkblog because it was quite a good video. Might as well learn it now, plus I can write a how to blog post.
Solution:
So I open up my linkblog on the search page. I search for: git patch “youtube.com”
Adding the url in quotes returns exact matches for the url. I hit the search button and receive a load of results. I use the browser in page search by doing ctr-f and type ‘patch’ in the browser search box window that opens in the top right of the browser. I hit enter and all occurrances of patch are highlighted in yellow. Hitting enter a few more times and the focus jumps down the page and BAM there is the tutorial: “Intro to git patch mode tutorial”. As an added bonus I notice that there is another video I posted about git patch right above it. Cool!

I click the cmd-click the domain at the end of the line and a new browser window tab opens up loading the youtube video. Oh so THAT’s how to git patch!
Here is a link to that day in my linkblog timeline. The video was by a chap named John Karey. Thanks for the video John.
-
Things I learnt as a solo developer building Linkblog.io
linkblog
Building a web application as a solo developer ain’t easy. There are an insane amount of things that need to be done and an almost unimaginable amount of decisions that need to be made…but it’s possible.
I wanted to take a few minutes to reflect on some of the things that I’ve learnt along the way:
- selecting the right technologies
- setting up consistent development environment
- using unix/linux tools effectively
- building a deployment pipeline
- architecting the app
- building a scaleable infrastructure
- testing, linting, logging, debugging
- securing components
- scripting and automation
- setting up server side and client side analytics
If you are a solo developer / small team just starting out on your building journey, feel free to get in touch tell me a bit about yourself. All these things are very fresh in my mind right now, and I am available for consulting gigs! Investing a bit of time and money now might save you weeks if not months of headaches later down the line.
-
Launch on Indie Hackers
linkblog
I unnoficially launched Linkblog.io yesterday on Indie Hackers. It’s been a long road with a seemingly endless onslaught of showstoppers, but the site is up and running and it’s built with a strong architecture, and running on a stable infrastructure with the possibility to scale if necessary.
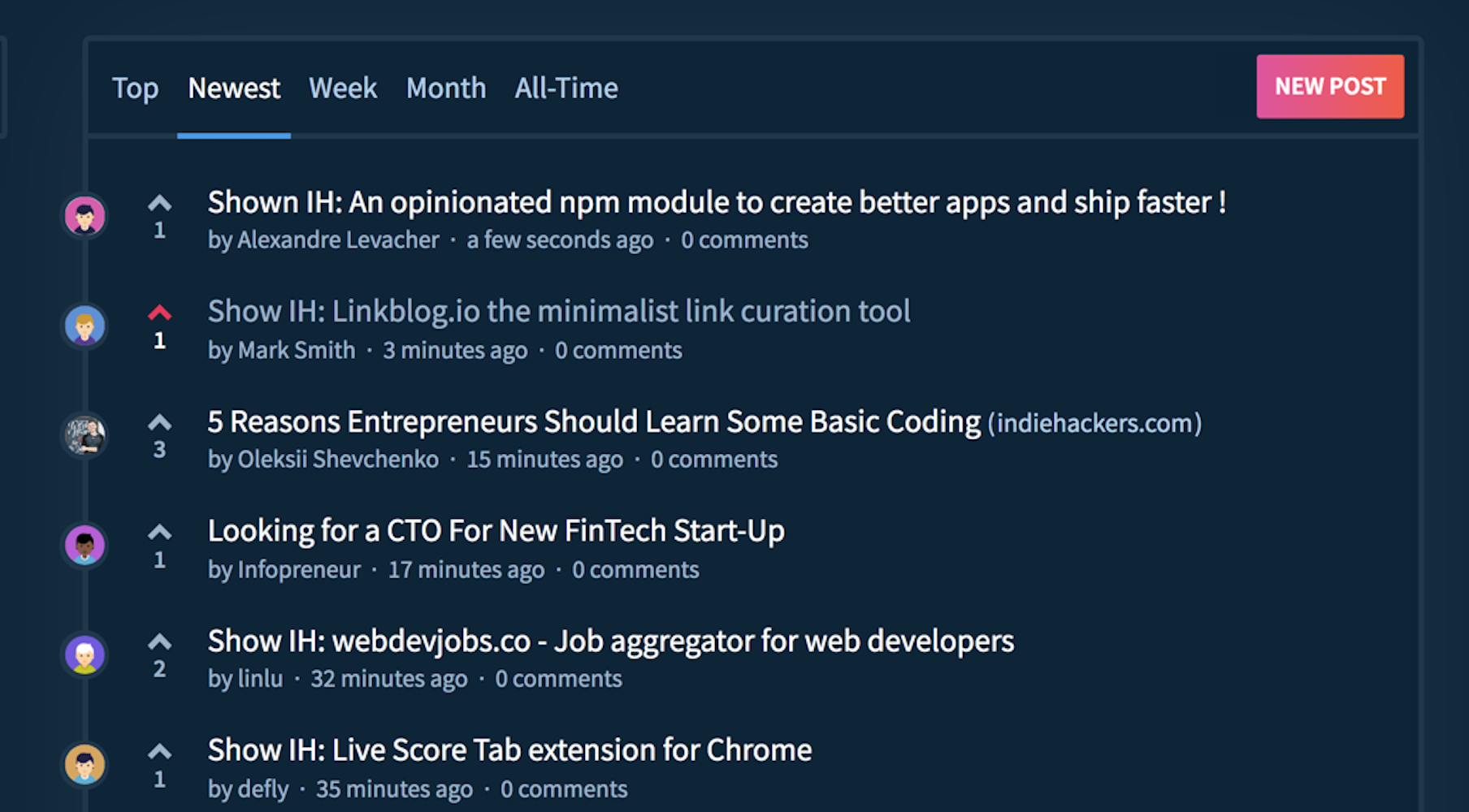
There was modest amount of hits from around the globe and I even got a comment, which was at least partially positive. After a few hours I realised that I had no way to differentiate between server-side side and client-side analytics. Oh noes!
So today I setup some new views and filters using custom dimensions to show each type of data. Things are looking much better now. :)
If you’re intersted in signing up, there is a promo code on the indie hackers post, your entire first year for the price of a few cups of coffee.
-
How to get an old jekyll blog active again
blogging static site generators jamstack
It was actually pretty straight forward. Check that the git remote is still configured, install the jekyll software, follow the instructions in the error messages. I had the dev version of the site back up within a few minutes.
$ cd $WEBSITES_DIR/blog.markjgsmith.com $ git status On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working tree clean $ cat .git/config | grep -A 2 remote\ \"origin\" [remote "origin"] url = https://github.com/mjgs/mjgs.github.io.git fetch = +refs/heads/*:refs/remotes/origin/* $ which jekyl $ gem install jekyll bundler $ bundle exec jekyll serve Could not find RedCloth-4.2.9 in any of the sources Run `bundle install` to install missing gems. $ bundle install $ bundle exec jekyll serve Configuration file: [WEBSITES_DIR]/blog.markjgsmith.com/_config.yml No post given to analyze. Try with -h Source: [WEBSITES_DIR]/blog.markjgsmith.com Destination: [WEBSITES_DIR]/blog.markjgsmith.com/_site Generating... done. Auto-regeneration: enabled for '[WEBSITES_DIR]/blog.markjgsmith.com' Configuration file: [WEBSITES_DIR]/blog.markjgsmith.com/_config.yml Server address: http://0.0.0.0:4000/ Server running... press ctrl-c to stop.I’m still a little fuzy on how to add posts. I tried to login to prose.io but the site wanted full access to all my repos on Github…a little excessive. Oh well editing in vim is good enough.
Last but not least push the changes to github…
git add * git commit -m "New post: How to get an old jekyll blog active again" git push -
Minimal Setup for Blogging with Jekyll
blogging jamstack static site generators
This initial post is to document how to configure the base Jekyll installation so that it’s ready for blogging, with posts displaying on the main page, an archives page that lists all the posts, an about page for a personal description and social media info in the footer.
The actual Jekyll installation is covered in the docs. It’s pretty straight forward. Setting up free hosting with Github is covered here.
For details of the modifications I made to the vanilla install have a look through the commits in the Github repo up to this commit.
I’m using Prose.io to edit posts in my web browser. Prose knows about Jekyll so you can create drafts and publish posts, it’s also open source.
-
Welcome to Jekyll!
jamstack static site generators blogging
You’ll find this post in your
_postsdirectory. Go ahead and edit it and re-build the site to see your changes. You can rebuild the site in many different ways, but the most common way is to runjekyll serve, which launches a web server and auto-regenerates your site when a file is updated.To add new posts, simply add a file in the
_postsdirectory that follows the conventionYYYY-MM-DD-name-of-post.extand includes the necessary front matter. Take a look at the source for this post to get an idea about how it works.Jekyll also offers powerful support for code snippets:
def print_hi(name) puts "Hi, #{name}" end print_hi('Tom') #=> prints 'Hi, Tom' to STDOUT.Check out the Jekyll docs for more info on how to get the most out of Jekyll. File all bugs/feature requests at Jekyll’s GitHub repo. If you have questions, you can ask them on Jekyll’s dedicated Help repository.
For enquiries about my consulting, development, training and writing services, aswell as sponsorship opportunities contact me directly via email. More details about me here.
subscribe via RSS